Adequate illustration of language linguistics needs access to large amounts of wisdom and domain-specific world data. previous add the sector was supported strictly applied mathematics techniques that didn't build use of information, on restricted penning data bases like WordNet, or on immense manual efforts like the CYC project. Here we tend to propose a completely unique technique, referred to as express linguistics Analysis (ESA), for fine-grained linguistics interpretation of unrestricted language texts. Our technique represents that means in an exceedingly high-dimensional area of ideas derived from Wikipedia, the biggest encyclopaedia living. we tend to expressly represent the that means of any text in terms of Wikipedia-based ideas. we tend to measure the effectiveness of our technique on text categorization and on computing the degree of linguistics connectedness between fragments of language text. exploitation ESA leads to vital enhancements over the previous state of the art in each tasks. significantly, thanks to the employment of natural ideas, the ESA model is simple to elucidate to human users. Recent proliferation of the globe Wide net, and customary convenience of cheap storage media to accumulate over time huge amounts of digital information, have contributed to the importance of intelligent access to the present information. it's the sheer quantity of information out there that emphasizes the intelligent facet of access—no one is willing to or capable of browsing through however a really tiny set of the information assortment, fastidiously designated to satisfy one’s precise info want. analysis in computing has long aimed toward endowing machines with the power to grasp language. {one of|one among|one in an exceedinglyll|one amongst|one in every of} the core problems with this challenge is method to|a way to} represent language linguistics in a way that may be manipulated by computers. previous work on linguistics illustration was supported strictly applied mathematics techniques, penning data, or elaborate endeavors to manually write in code massive amounts of data. the best approach to represent the text linguistics is to treat the text as Associate in Nursing unordered bag of words, wherever the words themselves (possibly stemmed) become options of the matter object. The sheer simple this approach makes it an inexpensive candidate for several info retrieval tasks like search and text categorization (Baeza-Yates & Ribeiro-Neto, 1999; Sebastiani, 2002). However, this easy model will solely be fairly used once texts ar fairly long, and performs sub-optimally on short texts. moreover, it will very little to handle the 2 main issues of language process (NLP), lexical ambiguity and semantic relation.
Research Article: Accounting & Marketing
Research Article: Accounting & Marketing
Research Article: Accounting & Marketing
Research Article: Accounting & Marketing
Research Article: Accounting & Marketing
Research Article: Accounting & Marketing
Research Article: Accounting & Marketing
Research Article: Accounting & Marketing
Research Article: Accounting & Marketing
Research Article: Accounting & Marketing
Posters-Accepted Abstracts: Accounting & Marketing
Posters-Accepted Abstracts: Accounting & Marketing
Posters-Accepted Abstracts: Accounting & Marketing
Posters-Accepted Abstracts: Accounting & Marketing
Posters & Accepted Abstracts: Business and Economics Journal
Posters & Accepted Abstracts: Business and Economics Journal
Posters & Accepted Abstracts: Business and Economics Journal
Posters & Accepted Abstracts: Business and Economics Journal
Scientific Tracks Abstracts: Business and Economics Journal
Scientific Tracks Abstracts: Business and Economics Journal
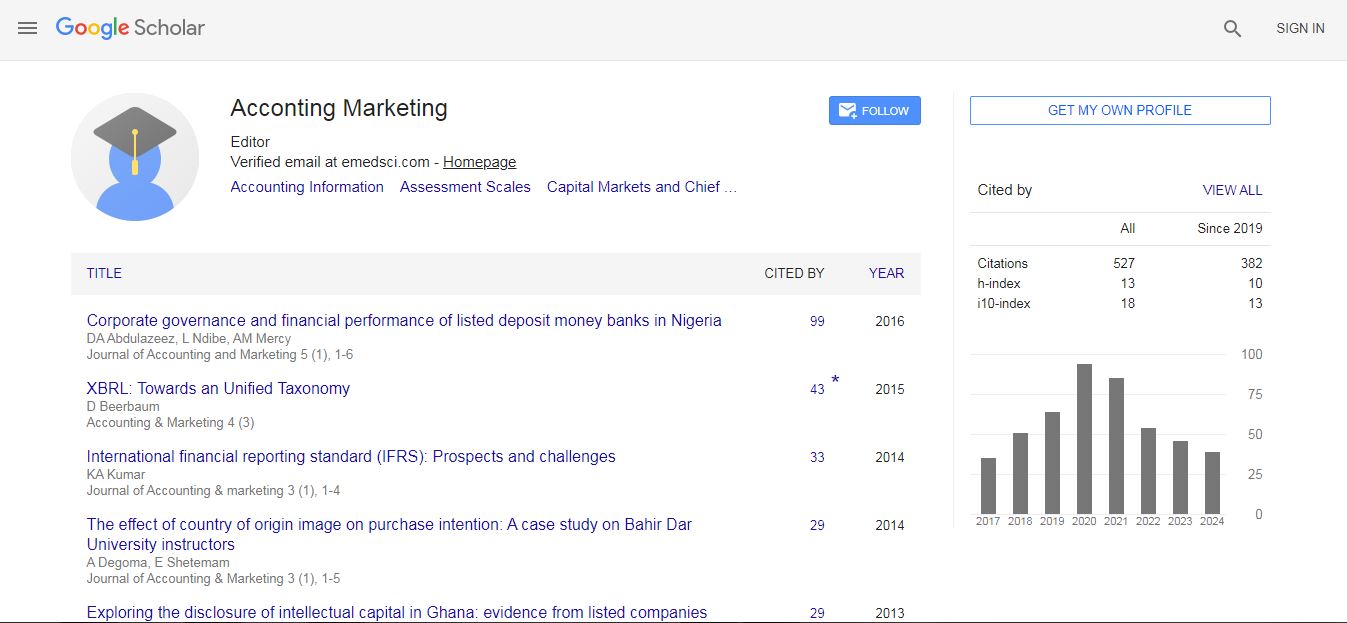
Accounting & Marketing received 487 citations as per Google Scholar report

 Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi 