Kanwal A, Fazal S, Bhatti AI and Khalid MA
Background: During last decades, an extraordinary improvement of bioinformatics has been observed that has prompted growth of a huge measure of biological data. The Bioinformatics and computational science aim to manage this huge volume of information. In the way biological data can be extracted, producing scientific knowledge, handling and mining huge information is at present a subject of incredible conspiracy and significance. Automation particularly in the information extraction step might be an essential technique to lessen the time important to finish an efficient research. However, the state of the art of automatically extricating information components from biological databases has not been all around portrayed.
Methods: Systematically PubMedInfo Crawler will identify potentially relevant articles and their details against different keywords. The included methodology met the following criteria: 1) Get keywords from user, send request to eutils.ncbi.nlm.nih.gov, fetch results from this server and then generate database to display output containing title and links of articles found against given keywords. 2) Transform these links into useful and structured form to get detailed information of each article: like PubMed id, title, abstract, journal name, authors’ name, publication date and country name to which authors belong. 3) Analyze the obtained details from different aspects that are discussed in detail in the methodology section.
Results: PubMedInfo Crawler (PMIC) has been developed to provide data extraction utilities for commonly used database PubMed. It is a simple web interface that enables input of query in the form of keyword and generates detailed useful information of each article against input keyword. Tool has been experimentally tested on different query keywords and has validated the results from PubMed. The overall accuracy of the crawler was found to be 96% for the number of articles against query terms. The tool is freely available.
Conclusion: This tools with help the public users to extract the data from Pubmed through an automatic way with less consumption of time. Furthermore it will help the researchers to accomplish their research in a better way with less effort.
Share this article
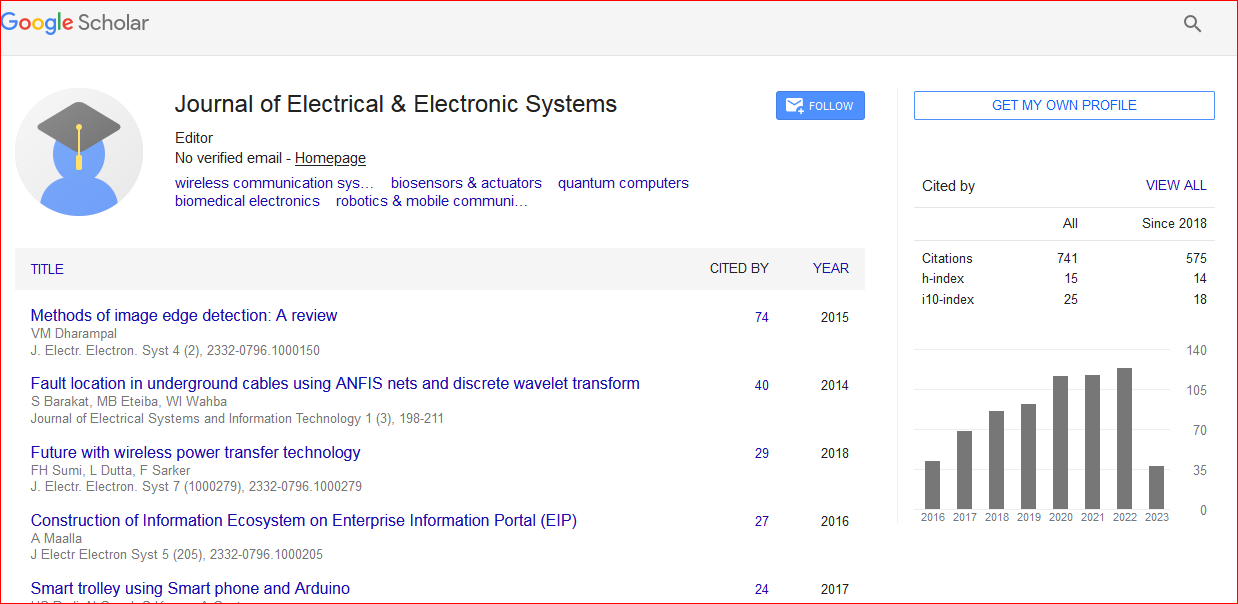
Journal of Electrical & Electronic Systems received 733 citations as per Google Scholar report