Brief Report - (2025) Volume 15, Issue 2
Received: 02-Jun-2025, Manuscript No. jpdbd-25-164656;
Editor assigned: 04-Jun-2025, Pre QC No. P-164656;
Reviewed: 16-Jun-2025, QC No. Q-164656;
Revised: 23-Jun-2025, Manuscript No. R-164656;
Published:
30-Jun-2025
, DOI: 10.37421/2153-0769.2025.15.413
Citation: Kairov, Tao. “Forging Connections: A Journey through the World of Metabolomics Databases.” Metabolomics 15 (2025): 413.
Copyright: © 2025 Kairov T. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Forging connections in the realm of metabolomic databases is an intricate and transformative journey that reflects the essence of systems biology and data-driven science. At its heart metabolomics is the comprehensive study of metabolites which are small molecules involved in metabolic processes within a biological system. These molecules are often the end products of cellular processes and their levels can provide a snapshot of the physiological state of a cell tissue or organism. As the study of metabolomics has advanced so too has the need for structured standardized and accessible repositories that house this growing ocean of data. This necessity gave rise to metabolomic databases which serve as the backbone of metabolomic research enabling scientists across the globe to store retrieve compare and analyze metabolic data efficiently.
The development and evolution of these databases are emblematic of the broader scientific movement toward open science and integrative research. At the inception of metabolomic research data collection was often localized and fragmented. Laboratories would conduct experiments using different analytical platforms such as mass spectrometry or nuclear magnetic resonance spectroscopy and the results would be stored in disparate formats. This heterogeneity posed a significant challenge for researchers seeking to perform cross-study comparisons or meta-analyses. The lack of standardization limited the reproducibility and scalability of findings. Thus the emergence of centralized metabolomic databases was not only timely but essential. They began to offer structured formats for data deposition metadata annotation and tools for data visualization and statistical analysis. These databases act as bridges connecting researchers from diverse disciplines and geographical regions enabling a truly collaborative scientific environment [1].
One of the defining features of metabolomic databases is their multidimensional nature. Unlike genomic or proteomic databases which often deal with linear sequences metabolomic data are inherently more complex. A single metabolite can participate in multiple pathways vary in concentration depending on time and tissue type and exhibit different ionization behaviors under different analytical conditions. Therefore capturing the full spectrum of metabolomic information requires databases to integrate chemical biological and analytical metadata. This includes molecular structures biochemical pathways organism-specific concentration ranges and instrument parameters. The ability to house such rich and interconnected data requires robust computational infrastructure and a clear understanding of the needs of the metabolomics community [2].
Over time various metabolomic databases have been developed each catering to specific needs or focusing on particular niches within the broader metabolomic landscape. Some databases emphasize metabolite identification and structural information while others prioritize pathway mapping or tissue-specific expression. These databases often cross-reference each other allowing for a network of knowledge to emerge. For example a researcher studying a particular disease can trace how a specific metabolite fluctuates in patient samples consult the biochemical pathways it is involved in and correlate this information with enzymatic functions or genetic mutations. This interconnectedness has transformed metabolomic databases from passive data repositories into active research tools. They now play a central role in hypothesis generation experimental design and even clinical translation.
One of the core strengths of metabolomic databases lies in their capacity to enhance data reproducibility and transparency. In the modern scientific era reproducibility is a cornerstone of credible research. By providing standardized protocols for data deposition and annotation these databases ensure that other researchers can understand replicate and build upon existing studies. This openness fosters a cumulative approach to science where knowledge is continuously refined and expanded. Furthermore the use of controlled vocabularies and ontologies in data annotation helps reduce ambiguity and aligns research outputs with broader biomedical terminologies. This is particularly important as metabolomics increasingly intersects with other omics fields such as genomics transcriptomics and proteomics. Interoperability between databases allows for multi-omic analyses which are crucial for understanding complex diseases and biological systems [3].
In addition to their scientific utility metabolomic databases are becoming increasingly important in translational medicine. As metabolomics moves from the lab bench to the clinic databases provide the foundation for biomarker discovery and validation. They allow researchers to compare metabolic profiles across healthy and diseased populations identify potential diagnostic or prognostic indicators and evaluate therapeutic responses. In personalized medicine metabolic data can inform treatment choices by revealing individual metabolic signatures. For instance in oncology metabolic reprogramming is a hallmark of cancer and metabolomic profiling can offer insights into tumor metabolism that guide targeted therapies. In such contexts metabolomic databases serve not only as scientific tools but also as enablers of better healthcare outcomes.
The success of metabolomic databases however depends heavily on community engagement and data sharing. Scientists must be willing to contribute their data to public repositories and to adhere to standards of quality and documentation. This cultural shift toward open data is not without challenges. Concerns about data misuse intellectual property and the effort required for proper data curation can hinder participation. Nevertheless the benefits of shared knowledge far outweigh the risks. Collaborative initiatives and consortia have been instrumental in promoting data sharing and in developing consensus standards for data formats metadata and reporting guidelines. These efforts ensure that metabolomic databases remain comprehensive current and useful [4,5].
Google Scholar Cross Ref Indexed at
Google Scholar Cross Ref Indexed at
Google Scholar Cross Ref Indexed at
Google Scholar Cross Ref Indexed at
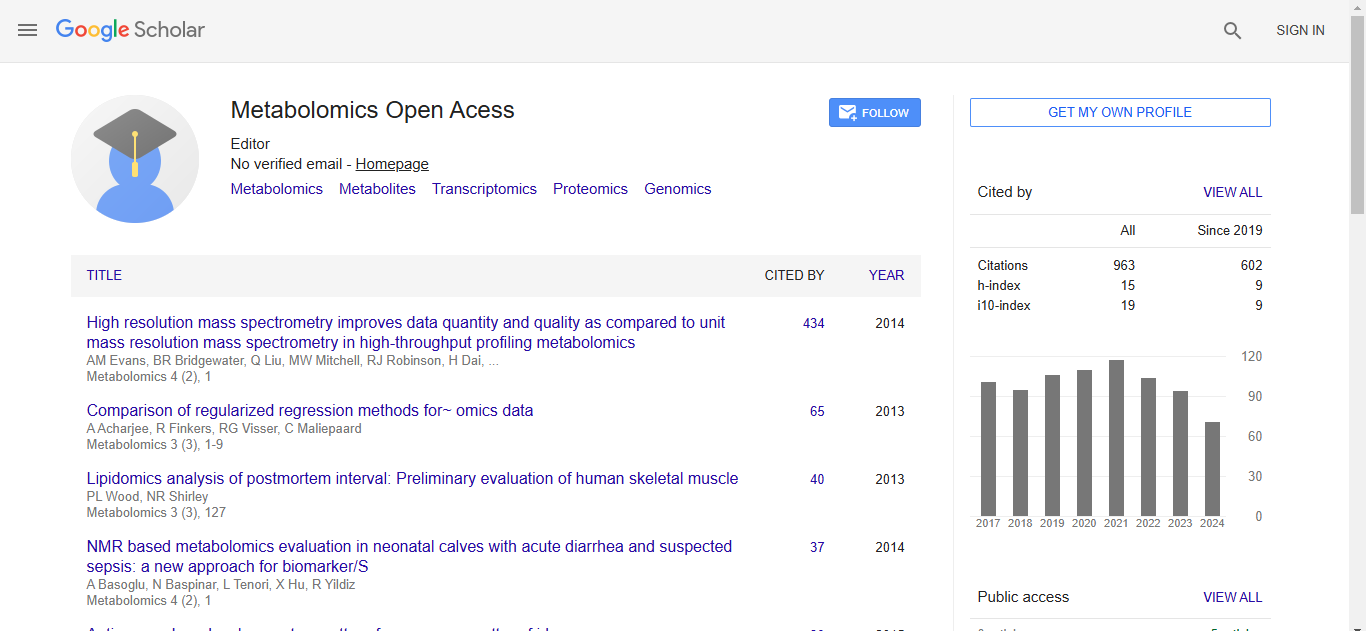
Metabolomics:Open Access received 895 citations as per Google Scholar report