Hypothesis - (2021) Volume 10, Issue 5
Received: 30-Oct-2019
Published:
25-Dec-2019
, DOI: 10.37421/2167-1095.2021.10.284
Citation: DodiIrwan Siregar. "Prediction of Life Expectancy at
Birth, Total (years) By Analyzing Capture fisheries production (metric tons) And
Industry (including construction), value added (current US$) In Italy 1990 –
2016." J Hypertens (Los Angel) 10 (2021): 284.
Copyright: © 2021 Dodiirwan Siregar. This is an open-access article distributed
under the terms of the Creative Commons Attribution License, which permits
unrestricted use, distribution, and reproduction in any medium, provided the
original author and source are credited.
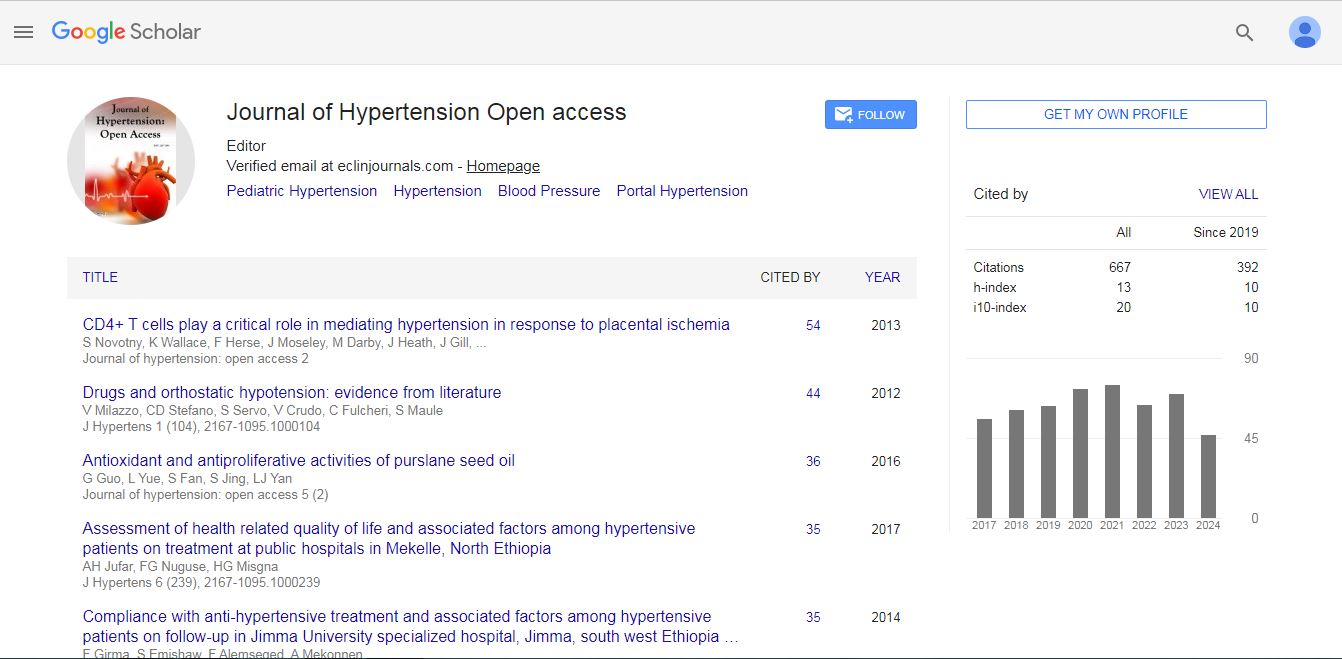
We consider the role played by an industry’s factor intensities and assess whether industries that have high physical and human capital intensities generate more pollution per unit of output. Fish from wild capture fisheries and aquaculture make a crucial contribution to both global food production and overall nutrition (SDG2, zero hunger; SDG3, good health and well-being), providing 3 billion people with almost 20% of their mean per capita intake of animal protein4 and providing essential micronutrients in otherwise deficient diets. The human health effects of omega-3 oils are the subject of much scientific and policy interest. The specific roles of a-linolenic acid (ALA, 18:3n-3), eicosapentaenoic acid (EPA, 20:5n-3) and docosahexaenoic acid (DHA, 22:6n-3) in preventing cardiovascular disease. This study uses multiple linear regression analysis to predict and predict changes in the value of certain variables when other variables change. Correlation is one of the statistical analysis techniques used to find the relationship of how strong the relationship between two or more variables that are quantitative. By using the Linearity Test (Lillie force test) where fcount> ftable is, 68.978411> 3.354 Then, Ho is rejected. This means that multiple linear regression analysis can be used to predict Life expectancy at birth, total (years in Italy by analyzing Variable Capture fisheries production (metric tons) and Industry (including construction), value added (current US$) data. Obtained the multiple linear regression equation is Y = 84.98627772 - 2.1921E-05X1 + 4.51839E-12X2, the correlation value of the variables above is 0.922937 the value is superior correlation scale ranging from 0.76 to 0.99. Is where t1 count< t table is -10.1945< 2.052, then Ho is accepted, meaning there is no significant effect partially between the Variable Life expectancy at birth and Capture fisheries production (metric tons). Then the value of the t2 count > t table is 2,638824 >2.052, Ho is rejected, it means that there is a large significant influence partially between the Life expectancy at birth and against the Industry (including construction), value added (current US$) variable in the Italy 1990 - 2016.
Life expectancy at birth, total (years), Capture fisheries production (metric tons), Industry, Country of Italy, Multiple Linear Regression, Correlations.
The equilibrium level of emissions for a given industry will reflect both demand and supply-side considerations. This provides us with a theoretical framework to explore the possible determinants of industry specific emissions intensity. We consider the role played by an industry’s factor intensities and assess whether industries that have high physical and human capital intensities generate more pollution per unit of output. Several studies have suggested a positive link between physical capital and pollution intensity in US industries (Antweiler, et al. 2001 and Cole and Elliott 2003).
There are different types of interactions between SDGs and the marine and terrestrial ecological processes and food production systems on which they rely. First, production from fishing, farming and aquaculture all support poverty alleviation (SDG1, no poverty; SDG10, reduced inequalities) by helping poorer people, especially those dwelling on coasts in sub-tropical and tropical regions, to maintain their food supply and income in variable environments (Bene,C., et al, 2010) . Second, fish from wild capture fisheries and aquaculture make a crucial contribution to both global food production and overall nutrition (SDG2, zero hunger; SDG3, good health and well-being), providing 3 billion people with almost 20% of their mean per capita intake of animal protein4 and providing essential micronutrients in otherwise deficient diets (Golden, C., 2016). Third, increases in fish production to meet the food and livelihood demands of the growing human population, projected to reach 9.7 billion by 20506, will increase pressure on marine and terrestrial ecosystems unless there are significant reductions in the environmental impact of many existing production systems (SDG12, responsible production and consumption; SDG14, life below water; SDG15, life on land). Last, all food production systems are both impacted by, and produce feedbacks to, climate change (SDG13, climate action) and opportunities for building climate-resilience may exist across sectors but may be masked within singlesector assessments. Here, we investigate and highlight the complex interplay between fisheries and other sectors under climate change and their potential implications for biodiversity conservation, livelihoods and food security. We show how an integrative land–sea and social–ecological approach is essential to reveal some of the major challenges for fisheries and other sectors that will have to be understood and managed to meet the SDGs
The human health effects of omega-3 oils are the subject of much scientific and policy interest. The specific roles of a-linolenic acid (ALA, 18:3n-3), eicosapentaenoic acid (EPA, 20:5n-3) and docosahexaenoic acid (DHA, 22:6n-3) in preventing cardiovascular disease (Hooper L., et al, 2006) and cancer4 are the subjects of active research.5 ALA is an essential nutrient which humans convert inefficiently to EPA and DHA. In relation to the cardio protective effects of fish oils, a systematic review shows there is more heterogeneity in the trial findings than previously recognized (Brunner E., 2006).
Collecting data
Once you decide on the type of data – quantitative or qualitative – appropriate for the problem at hand, you will need to collect the data. Generally, you can obtain data in four different ways:
Data from a published source
Data from a designed experiment
Data from a survey
Data collected observationally
Sometimes, the data set of interest has already been collected for you and is available in a published source, such as a book, journal, or newspaper. For example, you may want to examine and summarize the divorce rates (i.e., number of divorces per 1,000 populations) in the 50 states of the Indonesia. You can find this data set (as well as numerous other data sets) at your library in the statistical abstract of the Indonesia, published annually by the U.S. government. Similarly, someone who is interested in monthly mortgage applications for new home constructions would find this data set in the survey of current business, another government publication. Other example of published data source include the wall street journal (financial data), the sporting news (sport information), and Italyonline (accessed over the internet). (McClave and Sincich, 2000).
A statistical test procedure cannot prove the truth of a null hypothesis. When we fail to reject a null hypothesis, all the hypothesis test can establish is that the information in a simple of data is compatible with the null hypothesis. On the other hand, a statistical test can lead us to reject the null hypothesis, with only a small probability, α, of rejecting the null hypothesis when it is actually true. Thus rejecting a null hypothesis is stronger conclusion than failing to reject it.The null hypothesis is usually stated in such stated in such a way that if our theory is correct, then we will reject the null hypothesis. For example, our airplane seat designer has been operating under the assumption (the maintained or null hypothesis) that the population means hip width is 16.5 inches. Casual observation suggests that people are getting larger all the time. If we are larger and if the airplane wants to continue to accommodate the same percentage of the population, then the seat width must be increased. This costly change should be undertaken only if there is statistical evidence that the population hip size indeed larger. When using a hypothesis test we would like to find out whether there is statistical evidence against our current “theory,” or whether the data are compatible with it. With this goal, we set up the null hypothesis that the population mean is 16.5inches, H0:μ = 16.5, against the alternative that have shown that there has been a “statistically significant” increase in hip width.You may view the null hypothesis to be too limited in this case, since it is feasible that the population mean hip width is now smaller than 16.5 inches. The hypothesis test of the null hypothesis Ho:μ ≤ 16.5 against the alternative hypothesis H1:μ > 16.5 is exactly the same as the test for Ho:μ = 16.5 against the alternative hypothesis H1:μ = 16.5 against the alternative hypothesis H1>μ = 16.5. The test statistic and rejection region are exactly the same. For a onetail test you can form the null hypothesis in either of these ways. Finally, it is important to set up the null and alternative hypotheses before you analyze or oven collect the sample of data. Failing to do so can lead to errors in formulating the alternative hypothesis. Suppose that we wish to test whether μ > 16.5 and the sample mean is ŷ = 15.5. Does that mean we should set up the alternative μ < 16.5, to be consistent with estimate? The answer is no, the alternative is formed to state the conjecture that we wish to establish, μ > 16.5.(R. Carter Hill, William E. Griffiths and Guay C. Lim, 1976).
This chapter considers relationships between two measurements that can be represented by a line. Such relationships are called linear and their models are called regression models. As usual, we deal with settings in which there is variability in measurement. Observations in different circumstances but with the same x may give different values of y. Perhaps the true line goes through the first value of y and perhaps it goes through the second – more likely, it goes through neither. Despite there being strength in numbers, any finite sample gives less than perfect information about the line. Since anything uncertain has a probability distribution, the line itself has a probability distribution. Lines are specified by slopes and intercepts and so probabilities for lines are specified by probabilities for b and α. A major focus of this section is on the slope, b, because it indicates the degree of the relationship between x and y: increasing x by 1 unit means increasing y by b units. In particular, b = 0 means there is no relationship between x and y, at least not a linear relationship(D. A. Berry and B. W. Lindgren, 1990).
The regression effect arises in every aspect of life and yet few people appreciate its existence. As a result, some people mistakenly attribute change to an ineffective intervention. A golfer h(Xαas a terrible round and then takes a lesson – she does better the next time and praises her teacher. A baseball player is in a slump and changes bats – the next day he gets two hits and credits the bat. A woman a backache goes to a specialist and her backache improves – she thinks the specialist is a genius. A man is feeling depressed and goes to psychiatrist may be effective. But another explanation is possible and even likely in all this cases: the regression effect, also called regression to the mean. It is simple and ubiquitous: there are ups and downs in any sequence of exchangeable observation; drops tend to follow the ups and rises tend to follow the downs(D. A. Berry and B. W. Lindgren, 1990).
The first recorded observation of the regression effect was by Francis Galton. He found that seeds of mother sweet pea plants that happen to be larger than average tend to have daughters that are larger than average tend to have daughters that are smaller than average – but larger than themselves. The comparison from one generation to the next is a reversion or regression to the mean. Similarly, Galton noticed that sons of short men tend to be short – but not as short as their fathers. (Imagine what would happen to the population if the opposite were true and tall men tended to have sons taller than themselves and short men tended to have sons shorter than themselves!). Sports statistics that show the regression effect are readily(G. E. P. Box and G. C. Tiao, 1973).
Multiple regression analysis
Multiple regression analysis is a statistical technique that can be used to analyze the relationship between a single dependent (creation) variable and several independent variables. The objective of multiple regression analysis is to use the independent variables whose values are known to predict the single dependent value selected by the researcher. Each independent variable is weighted by the regression analysis procedure to ensure maximal prediction from the set of independent variable. The weights denote the relative contribution of the independent variables to the overall prediction and facilitate interpretation as to the influence of each variable in making the prediction, although correlation among the independent variables complicates the interpretative process. The set of weighted independent variables forms the regression variety, a linear combination of the independent variables that best predicts the dependent variable. The regression variety, also referred to as the regression equation or regression equation or regression model, is the most widely known example of vitiate among the multivariate techniques. Multiple regression analysis is a dependence technique. Thus, to use it you must be able to divide the variables into dependent and independent variables. Regression analysis is also a statistical tool that should be used only when both the dependent and independent variable are metric. However, under certain circumstances it is possible to include non-metric data either as independent variables (by transforming either ordinal or nominal data with dummy variable coding) or dependent variable. In summary, to apply multiple regression analysis: (1) the data must be metric or appropriately transformed, and (2) before deriving the regression equation, the researcher must decide which variable is to be dependent and which remaining variables will be independent (Cohen, J., and P. Cohen, 1983).
Term used to express the concept that the model processes the properties of additives and homogeneity. In a simple sense, linear models predict values that falls a straight line by having a constant unit change (slope) of the dependent variable for a constant unit change of the independent variable.
In the population models, Y = b0 + b1X1+ ε, the effect of a change of 1 in X1 is to add b1 (a constant) units of Y (Barnett, V., and T, Lewis, 1984).
Although there are many problems in which one variable can be predicted quite accurately in terms of another, it stands to reason that predictions should improve if one considers additional relevant information. For instance, we should be able to make better predictions of the performance of newly hired teachers if we consider not only their education, but also their years of experience and their personality. Also, we should be able to make better predictions of new textbook’s success if we consider not only the quality of the work, but also the potential demand and the competition.
Although there are many different formulas that can be used to express regression relationships among than two variables, most widely used are linear equations of the form;
y = β0 + β1x1 + β2x2 + … + βkxk
this is partly a matter of mathematical convenience and partly due to the fact that many relationships are actually of this form or can be approximated closely by linear equations. In the equations above, Y is the random variable whose values we want to predict in terms of given values of x1, x2, … , and xk, and β0, β1, β2, … , and βk, the multiple regression coefficients, are numerical constants that must be determined from observed data, (JhonE.Freund, 1962).
For each variable, the value of observations from one another, is not related. Multiple correlation is a correlation consisting of two independent variables (X1, X2) or more, and one dependent variable (Y). the relationship between variables can be described as follows (Figure 1): From the picture above the formulation of the problem consists of three or more problems, then multiple linear correlation is used.

Figure 1. Multiple linear correlation models.
Partial F (or t) values
The partial F-test is simply a statistical test for the additional contribution to prediction accuracy of a variable above that of the variables already in the equation. When a variable (Xα) is added to a regression equation after other variables are already in the equation, its contribution may be very small even though it has a high correlation with the dependent variable. The reason is that Xα is highly correlated with the variables already in the equation. The partial F value is calculated for all variables by simply pretending that each variable above all others in the equation indicates its low or insignificant partial F value for a variable not in the equation indicates its low or insignificant contribution to the model as already specified. A t value being approximately the square root of the fvalue (Cohen, J., and P. Cohen, 1983).
Partial F Values
As discussed earlier, two computational approaches – simultaneous and stepwise can be utilized in deriving discriminate functions. When the stepwise method is selected, an additional means of interpreting the relative discriminate power of the independent variables is available through the use of partial F values. This is accomplished by examining the absolute sizes of the significant F values and ranking them. Large F values indicate greater discriminatory power. In practice, rankings using the F-values approach are the same as the ranking derived from using discriminate weight, but the F values indicate the associated level of significance for each variable(Joseph F, H, JR, et al, 1998).
To test the hypothesis that the amount of variation explained by the regression model is more than the variation explained by the average, the F ratio is used. The test statistic F ratio is calculated as: F ratio = (SSE regression/df regression) / (SSE total/df residual)
Where
df regression = number of estimated coefficient (including intercept) – 1 df residual = sample size – number of estimated coefficient (including intercept).
The t-test The t test assesses the statistical significance of the difference between two independent sample means. If the t value is sufficiently large, then statistically we can say that the difference was not due to sampling variability, but represents a true difference. This is done by comparing the t statistic to the critical value of the t statistic (tcrit). If the absolute value of the statistic is greater than the critical value, this leads to rejection of the null hypothesis of no difference in the appeals of the advertising messages between groups. This means that the actual difference due to the appeals is statistically larger than the difference expected from sampling error. We determine the critical value (tcric) for our t statistic and test the statistical significance of the observed differences by the following procedure:
Compute the t statistic as the ratio of the difference between samples to the standard error.
Specify a type I error level (denoted as α, or significance level), which indicates the probability level the researcher will accept in concluding that the group means are difference when in fact they are not.
Determine the critical value (tcrec) by referring to the distribution with N1 + N2 – 2 degrees of freedom and specified α, where N1 and N2 are samples size.
If the absolute value of the computed t statistic exceeds tcrit, the researcher can conclude that the two advertising messages have different levels of appeal (i.e., μ1 ≠ μ2), with a type I error probability of α. The researcher can then examine the actual mean values to determine which group is higher on the dependent value (Hand, D. J., and C. C. Taylor, 1987).
Correlation coefficient (r)
Another measure of the relationship between two variables is the correlation coefficient. This section describes the simple linear correlation, for short linear correlation, which measures the strength of the linear association between two variables. In other words, the linear correlation coefficient measures how closely the points in a scatter diagram are spread around regression line. The correlation Calculated for population data is denoted by ρ (Greek letter rho) and the one calculated for sample data is, denoted by r. (Note that the square of the correlation coefficient is equal to theofdetermination) (Premm S. Mann, 1976). Coefficient that indicates the strength of the association between any two metric variables. The sign (+ or - ) indicates the direction of the relationship. The value can range from -1 to +1, with +1 indicating a perfect positive relationship, 0 indicating no relationship, and -1 indicating a perfect negative or reverse relationship (as one variable grows larger, the other variable grows smaller) (Cohen, J., and P. Cohen, 1983).
The coefficient of correlation (r) is simply the square root of the coefficient of determination (r2). Thus, four our, the coefficient of correlation is r = √r2 = √.982 = .991. As you can see, r is a positive value in this case, but r can also be negative. The algebraic sign for r is always the same as that of b in the regression equation. The coefficient of correlation isn’t as useful as the coefficient of determination, since it’s an abstract decimal and isn’t subject to precise interpretation. (As the square root of a percentage, it cannot itself be interpreted in percentage terms). But r does provide a scale against which the closeness of the relationship between -1.00 and +1.00. When r is zero, there is no correlation, and when r = -1.00 or +1.00, there is perfect correlation. Thus, the closer r is to its limit of ±1.00, the better the correlation, and the closer it is zero, the poorer the relationship between the variables (Sanders and Smidt, 2000) (Table 1).
| Value of Correlation (r) | Interpretation (r) |
|---|---|
| 0,00 – 0,25 | Doubtful Correlation |
| 0,26 – 0,50 | Fair Correlation |
| 0,51 – 0,75 | Good Correlation |
| 0,76 – 1,00 | Superior Correlation |
Null hypothesis and alternative hypothesis for f-test Null Hypothesis (Ho) that is, linear regression analysis cannot be used in analyzing the effect of Capture fisheries production (metric tons) (X1) and Industry (including construction), value added (current US$) (X2) on Life expectancy at birth, total (years) (Y) (Table 2).
| Years | Capture fisheries production (metric tons) (X1) | Industry (including construction), value added (current US$) (X2) | Life expectancy at birth, total (years) (Y) |
|---|---|---|---|
| 990 | 376932,2 |
3,295E+11 | 76,97073171 |
| 1992 | 396467,5 | 3,50177E+11 | 77,4195122 |
| 1993 | 397542,4 | 2,79224E+11 | 77,72195122 |
| 1994 | 399338,8 | 2,88211E+11 | 77,92195122 |
| 1995 | 397882,1 | 3,07864E+11 | 78,17073171 |
| 1996 | 367754,5 | 3,386E+11 | 78,52195122 |
| 1997 | 345649,6 | 3,1558E+11 | 78,82439024 |
| 1998 | 308484,7 | 3,19902E+11 | 78,97560976 |
| 1999 | 284822,3 | 3,08056E+11 | 79,42439024 |
| 2000 | 304156,8 | 2,77667E+11 | 79,77804878 |
| 2001 | 312408,7 | 2,81035E+11 | 80,12682927 |
| 2002 | 271902,1 | 3,04461E+11 | 80,22926829 |
| 2003 | 297700,8 | 3,68721E+11 | 79,98292683 |
| 2004 | 288939,8 | 4,21754E+11 | 80,7804878 |
| 2005 | 298584,1 | 4,3159E+11 | 80,78292683 |
| 2006 | 317852,7 | 4,55164E+11 | 81,28292683 |
| 2007 | 289479,5 | 5,24138E+11 | 81,43414634 |
| 2008 | 237619,5 | 5,63855E+11 | 81,48536,585 |
| 2009 | 254520 | 4,79278E+11 | 81,63658537 |
| 2010 | 234959,5 | 4,65915E+11 | 81,203658537 |
| 2011 | 217829,7 | 4,94836E+11 | 82,18780488 |
| 2012 | 202430,4 | 4,44135E+11 | 82,23902439 |
| 2013 | 177915,7 | 4,5439E+11 | 82,6902439 |
| 2014 | 183846 | 4,52241E+11 | 83,0902439 |
| 2015 | 198768,9 | 3,88171E+11 | 82,54,390244 |
| 2016 | 198130 | 4,02238E+11 | 83,24,390244 |
| S | 7973246 | 1,03831E+13 | 2166,521,951 |
Alternative Hypothesis (Hα) that is, linear regression analysis can be used in analyzing the effect of Capture fisheries production (metric tons) (X1) and Industry (including construction), value added (current US$) (X2) on Life expectancy at birth, total (years) (Y).
The F-test
The partial F-test is simply a statistical test for the additional contribution to prediction accuracy of a variable above that of the variables already in the equation. When a variable (Xα) is added to a regression equation after other variables are already in the equation, its contribution may be very small even though it has a high correlation with the dependent variable. F value is 68,97830629 and F ratio is 3,183. F value > F ratio is 68,97830629> 3,183 Then, Ho is rejected. So, multiple linear regression analysis can be used in analyzing the influence of Capture fisheries production (metric tons) (X1) and Industry (including construction), value added (current US$) (X2) on Life expectancy at birth, total (years) (Y).
Multiple regression analysis
Although there are many different formulas that can be used to express regression relationships among than two variables, most widely used are linear equations of the form;
y = β0 + β1x1 + β2x2 + … + βkxk
The results of multiple linear regression analysis obtained the equation Life expectancy at birth, total (years) (Y) by analyzing the Capture fisheries production (metric tons) (X1) as (X1) to Life expectancy at birth, total (years) (X2) we get the formula for multiple linear regression equation as follows:
Y = 84.98627772 - 2.1921E-05X1 + 4.51839E-12X2
By using the above equation we can predict or predict Life Expectancy in Italy in the future by using these multiple linear regression equations.
Correlation coefficient (r)
Partial correlation coefficient
Value that measures the strength of the relationship between the criterion or independent variable and a single independent variable when the effects of another independent variables in the model are held constant. For example, ry,x2,x1, measures the variation in Y associated with X2, when the effect of X1 on both X2 and Y is held constant. This value is used in sequential variable selection methods of regression model estimation to identify the independent variable with the greatest incremental predictive power beyond the independent variables already in the regression model (Barnett, V., and T, Lewis, 1984). Value that measures the strength of the relationship between the criterion or independent variable and a single independent variable when the effects of another independent variables in the model are held constant. For ry,x2,x1, measures the variation in Y associated with X2, when the effect of X1 on both X2 and Y is held constant. The value of ry,x2,x1 is 0,922936706 with the interpretation being Superior Correlation which ranges from 0.75 to 0.99. For ry,x1, measures the variation in Y associated with X1. The value ry,x1 is -0,9489876 with the interpretation being Superior Correlation, which ranges from - 0.75 to - 0.99. For ry,x2 measures the variation in Y associated with X2. The value ry,x2is 0,715631963 with the interpretation being Negative Superior Correlation, which ranges from - 0.76 to - 0.99. For rx1,x2 measures the variation in X1 associated with X2. The value of rx1,x2 is -0,631988784 with the interpretation being negative Superior Correlation, which ranges from - 0.76 to - 0.99.
Partial influence test (t-test) between X1 and Y
Null Hypothesis (Ho) that is, there is no significant (very large) effect partially between Capture fisheries production (metric tons) as variable X1 on Life expectancy at birth, total (years) as Y.
Alternative Hypothesis (Hα) that is, there is a significant (very large) effect partially between Capture fisheries production (metric tons) as variable X1 to Life expectancy at birth, total (years) as Y (Figure 2).
t1 value is -10,19446442 and t ratio is 2,052. So, t1 value < t ratio is the value of -10,19446442 < 2,052; then Ho is accepted meaning, there is no significant (very large) effect partially between Capture fisheries production (metric tons) as variable X1 to Life expectancy at birth, total (years) as Y.

Figure 2: Capture fisheries production (metric tons) plot to Life expectancy at birth, total (years)
From the results of the study it can be concluded as follows: F value > F ratio that is 68,97830629> 3,183 Then, Ho is rejected. that is, linear regression analysis can be used in analyzing the influence of the dependent variable (free) Fossil value of fuel energy consumption (% of total) and Industry (including construction), value added (current US$) on the independent variable (dependent) Life expectancy at birth, total (years). The multiple linear regression equation of these variables is as follows.
Y = 84.98627772 - 2.1921E-05X1 + 4.51839E-12X2
Correlation (interrelation) of variables in multiple linear regression (ry,x1,x2) that is, independent variable (free); Life expectancy at birth, total (years) is variable (Y) of the dependent variable (free) Fossil value of fuel energy consumption (% of total) (X1) and Industry (including construction), value added (current US$) (X2) obtained results (ry,x1,x2 is 0.922936706) with interpretation is Superior Correlation which ranges from 0.75 to 0.99. For t₁ value <t ratio; that is -10,19446442< 2.052, so, Ho is accepted, that is a significant (large) relationship betw een Life expectancy at birth, total (years) with the Capture fisheries production (metric tons).
For t2 value > t ratio that is 2,638823648 > 2,052, then Ho is rejected, it means, there is a no significant / close relationship between Life expectancy at birth, total (years) with Industry (including construction), value added (current US$).
Without reservation, we would like thank you to my parents, my father; Misran Siregar and my Mother; YurnitaYunus, and thank you to reviewers and the seminar participants at persada university in pekanbaru for their helpful comments and suggestions, as well as the World Development Indicators “World Bank Data”. The views expressed in this paper are those of the authors.
Journal of Hypertension: Open Access received 614 citations as per Google Scholar report