Adequate representation of natural language semantics requires access to vast amounts of common sense and domain-specific world knowledge. Prior work in the field was based on purely statistical techniques that did not make use of background knowledge, on limited lexicographic knowledge bases such as WordNet, or on huge manual efforts such as the CYC project. Here we propose a novel method, called Explicit Semantic Analysis (ESA), for fine-grained semantic interpretation of unrestricted natural language texts. Our method represents meaning in a high-dimensional space of concepts derived from Wikipedia, the largest encyclopedia in existence. We explicitly represent the meaning of any text in terms of Wikipedia-based concepts. We evaluate the effectiveness of our method on text categorization and on computing the degree of semantic relatedness between fragments of natural language text. Using ESA results in significant improvements over the previous state of the art in both tasks. Importantly, due to the use of natural concepts, the ESA model is easy to explain to human users. Recent proliferation of the World Wide Web, and common availability of inexpensive storage media to accumulate over time enormous amounts of digital data, have contributed to the importance of intelligent access to this data. It is the sheer amount of data available that emphasizes the intelligent aspect of access—no one is willing to or capable of browsing through but a very small subset of the data collection, carefully selected to satisfy one’s precise information need. Research in artificial intelligence has long aimed at endowing machines with the ability to understand natural language. One of the core issues of this challenge is how to represent language semantics in a way that can be manipulated by computers. Prior work on semantics representation was based on purely statistical techniques, lexicographic knowledge, or elaborate endeavors to manually encode large amounts of knowledge. The simplest approach to represent the text semantics is to treat the text as an unordered bag of words, where the words themselves (possibly stemmed) become features of the textual object. The sheer ease of this approach makes it a reasonable candidate for many information retrieval tasks such as search and text categorization (Baeza-Yates & Ribeiro-Neto, 1999; Sebastiani, 2002). However, this simple model can only be reasonably used when texts are fairly long, and performs sub-optimally on short texts. Furthermore, it does little to address the two main problems of natural language processing (NLP), polysemy and synonymy.
Short Review: Advances in Robotics & Automation
Short Review: Advances in Robotics & Automation
Research Article: Advances in Robotics & Automation
Research Article: Advances in Robotics & Automation
Review Article: Advances in Robotics & Automation
Review Article: Advances in Robotics & Automation
Research Article: Advances in Robotics & Automation
Research Article: Advances in Robotics & Automation
Editorial: Advances in Robotics & Automation
Editorial: Advances in Robotics & Automation
Posters & Accepted Abstracts: Journal of Material Sciences & Engineering
Posters & Accepted Abstracts: Journal of Material Sciences & Engineering
Posters & Accepted Abstracts: International Journal of Sensor Networks and Data Communications
Posters & Accepted Abstracts: International Journal of Sensor Networks and Data Communications
Posters & Accepted Abstracts: International Journal of Sensor Networks and Data Communications
Posters & Accepted Abstracts: International Journal of Sensor Networks and Data Communications
Scientific Tracks Abstracts: Journal of Material Sciences & Engineering
Scientific Tracks Abstracts: Journal of Material Sciences & Engineering
Scientific Tracks Abstracts: Journal of Material Sciences & Engineering
Scientific Tracks Abstracts: Journal of Material Sciences & Engineering
Scientific Tracks Abstracts: Journal of Material Sciences & Engineering
Scientific Tracks Abstracts: Journal of Material Sciences & Engineering
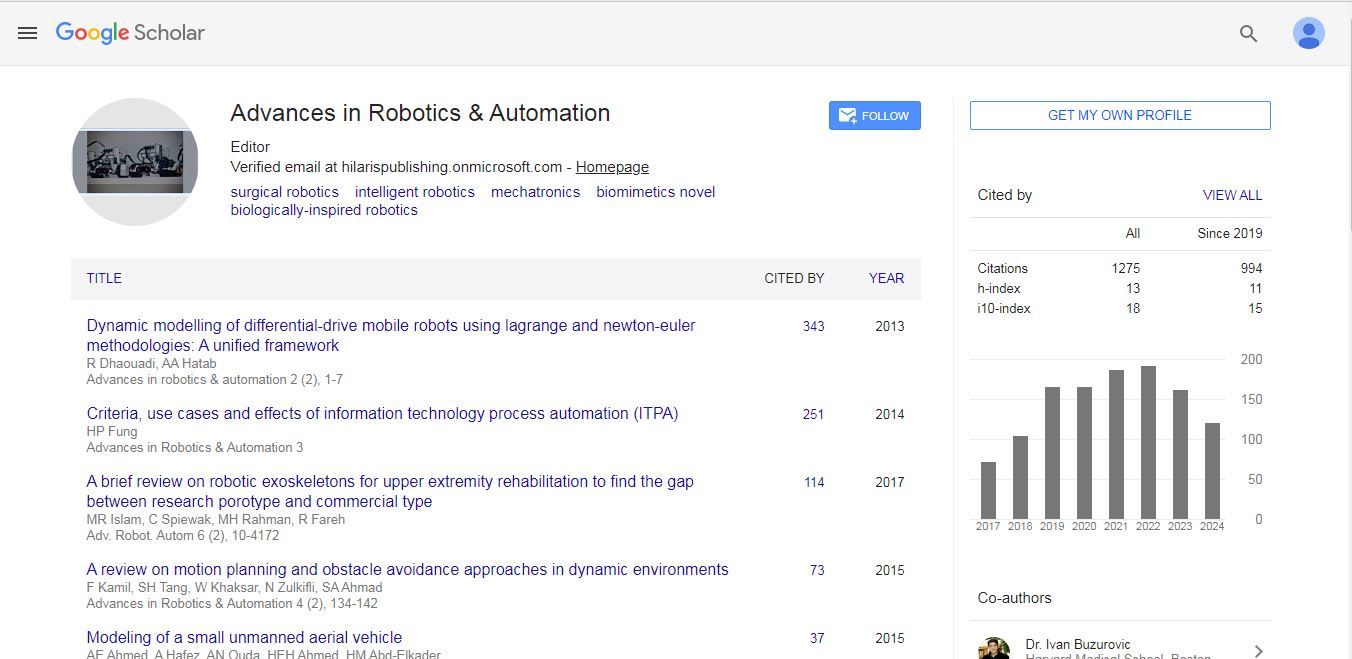
Advances in Robotics & Automation received 1275 citations as per Google Scholar report

 Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi 