Begonya Comin-Anduix
Scientific Tracks Abstracts: J Comput Sci Syst Biol
Extracting relevant information from complex data sets and the identification of novel compounds are the major bottlenecks in (microbial) metabolomics research. Compared to a focused targeted approach this is even more important in untargeted metabolomics, aiming for the identification of all compounds produced by a particular bacterial strain. Many of these compounds are part of primary metabolism and therefore out of scope when research concentrates on secondary metabolites. Other metabolites may be very common for a certain genus of bacteria and already well known, but the large subset of compounds that is ?really new? is hard to identify. By combining targeted and untargeted metabolomics approaches, including searches in freely available data bases, it is possible to narrow down and identify numerous features derived from HPLC-high resolution MS/MS measurements. An automated feature finding algorithm extracted around 2000 ? 5000 features within one HPLC-MS chromatogram. In a first step, these features were subjected to a search against an in-house database using accurate mass, isotope pattern fit, and retention time in order to identify already known compounds. Untargeted metabolite profiling, using statistical methods such as ANOVA, t-test as well as PCA analysis, could identify features related to the growth of the bacteria by comparing myxobacterial extracts to blank samples (growth medium). These features were automatically added to a scheduled precursor list (SPL) to focus fragmentation experiments to the relevant subset of compounds within the complex mixture. This enabled a fragmentation of even low abundant features which might have been missed during an automatic precursor selection without predefined compounds of interest. High resolution full scan MS and MS/MS spectra were used to identify target metabolites by queries in open source libraries (e.g. METLIN). Remaining unidentified features were subsequently compared to an in-house database to identify putative derivatives of known compounds based on a similar fragmentation pattern.
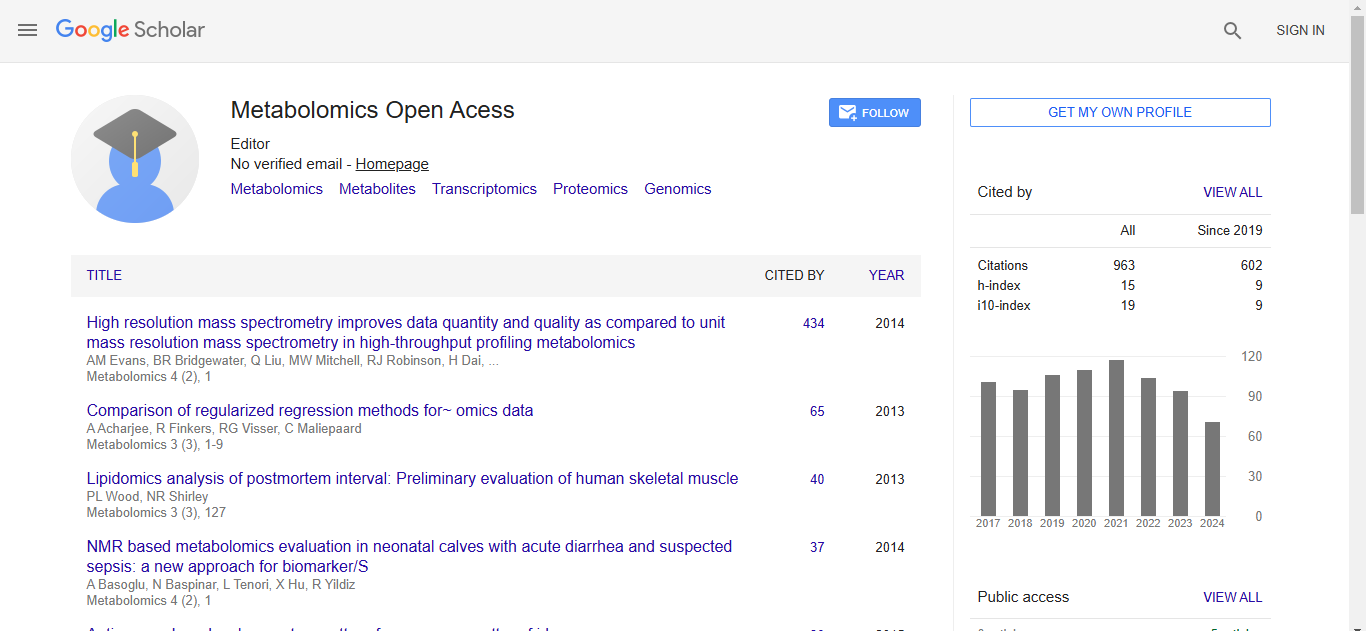
Metabolomics:Open Access received 895 citations as per Google Scholar report

 Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi 