Review - (2022) Volume 16, Issue 7
Received: 04-Jul-2022, Manuscript No. JMGM-22-72239;
Editor assigned: 05-Jul-2022, Pre QC No. P-72239;
Reviewed: 12-Jul-2022, QC No. Q-72239;
Revised: 19-Jul-2022, Manuscript No. R-72239;
Published:
26-Jul-2022
, DOI: 10.37421/1747-0862.2022.16.565
Citation: Thomas, Mark. “Review on Chromosomal Rearrangement and Structural Modifications.” J Mol Genet Med 16 (2022): 565.
Copyright: © 2022 Thomas M. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Chromosomal rearrangement • Genome modifications • Translocations • Genetic Alterations
In the late 1970s, the fluorescent in situ hybridization (FISH) method was created. By giving methods for viewing particular loci on metaphase chromosomes, FISH significantly increased the resolution of conventional karyotyping. FISH additionally provided a method for examining non-dividing cells by enabling the quantitative examination of chromosomal changes in interphase cells. About 40 different applications of FISH have been identified thus far, and the technology is still being improved and refined. While some of these applications focus on answering particular biological concerns, others are frequently utilised for chromosomal analysis in cancer cells and for the clinical assessment of patient samples.
Generally speaking, the most widely used FISH techniques call for the creation of a locus-specific probe (LSP) targeting a gene of interest (typically an oncogene or a tumour suppressor gene) that is labelled with one fluorochrome, along with one or more reference probes (a subcentromeric probe mapping to the same chromosome as the LSP of interest or a probe mapping to a region flanking the LSP) that are labelled with a In order to accurately and thoroughly analyses chromosome alterations, including visualization of chromosome breakpoints, copy number alterations (gains and losses), and inversion of chromosomal regions, a variety of probes can be used in various combinations depending on the particular loci of interest.
FISH is a low-cost method that offers the benefits of single-cell analysis and the facilitation of characterization of genomic areas that are notoriously challenging to examine with other methods (e.g., structural alterations that map to repetitive regions such as per centromeres and telomeres). A spectra cube is necessary for the more advanced FISH technique known as spectral karyotyping (SKY) (interferometer). With its unique ability to see intricate structural changes, SKY is based on the combinatorial usage of paint probes that target all chromosomes in a single hybridization. In order to advance the area of molecular cytogenetic analysis and better comprehend the intricacy of chromosome changes in cancer, the use of SKY in the analysis of human and mouse samples has been crucial. The complexity of previously recognized breakpoints has been streamlined, and cases that were challenging to characterize due to poor spreads or contracted metaphase chromosomes, highly rearranged karyotypes with a large number of marker chromosomes, or subtle chromosomal aberrations have now been better understood. SKY has additionally shown to be an effective method for analyzing mouse chromosomes. The difficulties of analyzing murine chromosomes that are identical in size and are acrocentric have spurred the demand for better cytogenetic analysis techniques, which has led to the use of genetically modified mice as model systems for human cancer. As a result, karyotyping is highly challenging in mice since the distinctive banding pattern generally used to identify human chromosomes is less useful in mice.
Additionally, there aren't many cytogeneticists skilled in karyotyping mouse chromosomes currently. The use of SKY to describe the karyotype of several murine models is described in more than 160 studies. SKY has shown to be a very useful tool for us in evaluating structural changes leading to intricate rearrangements in mouse chromosomes. One of the most fundamental issues in evolutionary biology is where new genes come from. For a thorough explanation of evolutionary processes, it is crucial to comprehend the origins of new genes. The genetic building blocks necessary for phenotypic variety in natural populations are produced via mutation. Change cannot be brought about by selection without this fresh genetic material. The identification of single nucleotide polymorphisms (SNPs) in population genetic data has become easy thanks to deep genome sequencing. Contrarily, structural variants and duplications continue to receive little research, in part because it is more challenging to spot them in sequence data. We can start investigating the entire implications of these complicated changes in nature thanks to advancements in next-generation sequencing quality and throughput. Rearrangements of the chromosomes play a role in species-to-species genomic divergence. While the genome composition of different organisms shows striking similarities, syntenic blocks in the genome become disorganised throughout time. It is known that chromosomal rearrangements can shift genes and affect how they are expressed in primates. Similar positional effects seen in transgenic constructs can be compared to this spontaneous variation from the genomic vicinity.
However, these mutations have effects that go far beyond slight variations in mRNA levels. Gene sequences can change as a result of mutations that replicate and reorder DNA fragments. They may duplicate entire genes, create chimaera genes, or create different gene constructions. These mutations do not fully examine the whole range of novel gene production. De novo exon production occurs when duplicated segments fail to obey gene boundaries, according to recent research. These novel genes might give a genetic explanation to patterns that resemble de novo gene synthesis. When inversions changed gene sequences at breakpoints, similar occurrences of novel gene creation were seen. Whole genome analyses of gene reorganisations and the emergence of novel genes in wild populations are, however, missing. Different mutational mechanisms, such as DNA replication, repair, and recombination processes, lead to structural variants. It is vital to study these mechanisms because doing so will enable us to better comprehend how cells react to DNA damage and the characteristics of the DNA sequences implicated in these rearrangements. Furthermore, the analysis of rearrangement breakpoints by DNA sequencing enables us to recognise the hallmarks of these processes and pinpoint risk factors for such rearrangements, assisting us in deducing the mechanisms underlying their occurrence. It is possible to examine rearrangements and their breakpoints using a variety of techniques. Using G-banding karyotyping, significant imbalances larger than 5–10 Mb can be found. A method with even higher resolution, chromosomal microarray, may measure copy number across the genome and discover submicroscopic changes.
Techniques for next-generation sequencing (NGS) are utilised to find both balanced and unbalanced structural changes. These methods are frequently employed in conjunction with fluorescent in situ hybridization (FISH), which can reveal the positions and directions of the mutations by utilising fluorescentlabeled DNA probes specific to particular chromosomal locations. Using NGS methods such long-read whole genome sequencing, mate-pair sequencing, and optical genome mapping methodology, breakpoint location study can be carried out. Sanger sequencing, which can validate breakpoints at the nucleotide level, is essential for a more thorough investigation and to aid in understanding the mechanism of rearrangement creation. Some aspects of the genomic architecture may cause genome instability, which may make some parts of the genome more prone to rearrangement. Similar breakpoints, sizes, and genetic content are presented by recurrent rearrangements, and these traits can be shared by unrelated people. On the other hand, each unrelated individual's non-recurrent rearrangements are distinct and have their own breakpoints, sizes, and genomic contents. However, a genetic overlap region linked to genomic diseases may be shared by several of them. The majority of these rearrangements result from replication processes following a replication fork breakage or stalling, or from recombination or repair mechanisms following a double-strand break (DSB). A double strand break can either be two-ended or single-ended and occurs when the phosphodiester backbone of two complementary DNA strands is disrupted.
Reactive oxygen species from oxidative metabolism, ionising radiation like X-rays, gamma rays, and UV light, accidentally acting nuclear enzymes, and when there is physical or mechanical stress on the DNA, such as during the breakage-fusion-bridge cycles after the formation of a chromosome with two centromeres, are just a few of the potential causes of pathological DSBs (dicentric chromosome). When the replication fork comes across a nick, which is a break in a single strand of the DNA backbone, pathological DSBs can also develop. Different recombination or repair mechanisms that aim to fix the DSB may result in chromosomal rearrangements. Replication stress, such as DNA lesions, interactions with RNA, and metabolic circumstances, can cause replication forks to break or halt. Alternately, secondary DNA structures (non-B DNA), which are typically generated in regions of the genome containing repetitive sequences, might cause replication forks to malfunction. For instance, mirror repetitions can create H-DNA (triple-helical DNA), inverted repeats have been linked to the production of hairpins in single-stranded DNA, and direct tandem repeats can create quadruplex, left-handed Z-DNA, and slipped-strand DNA depending on their base makeup (S-DNA). These secondary DNA structures have been linked to the inhibition of a number of DNA polymerases as well as the confusion of the DNA replication machinery, which leads to replication forks breaking or stalling and enables complicated rearrangements to occur as a result of template-switching events.
Microhomology, or short DNA segments with homology in their sequences, which is typically described as a string of nucleotides ( 70) near both broken ends involved in the rearrangement, can sometimes cause them to happen. Non-Allelic Homologous Recombination (NAHR), which occurs between Low Copy Repeats (LCRs), is the mechanism responsible for the majority of recurrent rearrangements, which leads to breakpoint clustering close to these areas. Low copy repeats, sometimes referred to as segmental duplications, are DNA blocks with over 97% identity between their sequences that range in size from 10 to 400 kb. They may include paralogous sequences, repetitive gene clusters, pseudogenes, or genes. LCRs' comparable sequences make them suitable substrates for homologous recombination [1-5].
Their dimensions, degree of homology, orientation, and relative positioning have an impact on the genome's architecture, creating unstable regions that are more likely to undergo rearrangements. Because of the high degree of sequence identity across non-allelic copies of LCRs, NAHR can happen after a DSB during meiosis or mitosis. Because of this misalignment, the offspring cells' genomes are rearranged due to an unequal crossing over event. An intrachromosomal, intrachromatid, or interchromosomal mechanism is known as NAHR. NAHR between LCRs in sister chromatids of the same chromosome that are oriented directly toward one another (intrachromosomal or interchromatid) results in reciprocal duplications and deletions, whereas inversions result from LCRs that are oriented in the opposite direction.
Google Scholar, Crossref, Indexed at
Google Scholar, Crossref, Indexed at
Google Scholar, Crossref, Indexed at
Google Scholar, Crossref, Indexed at
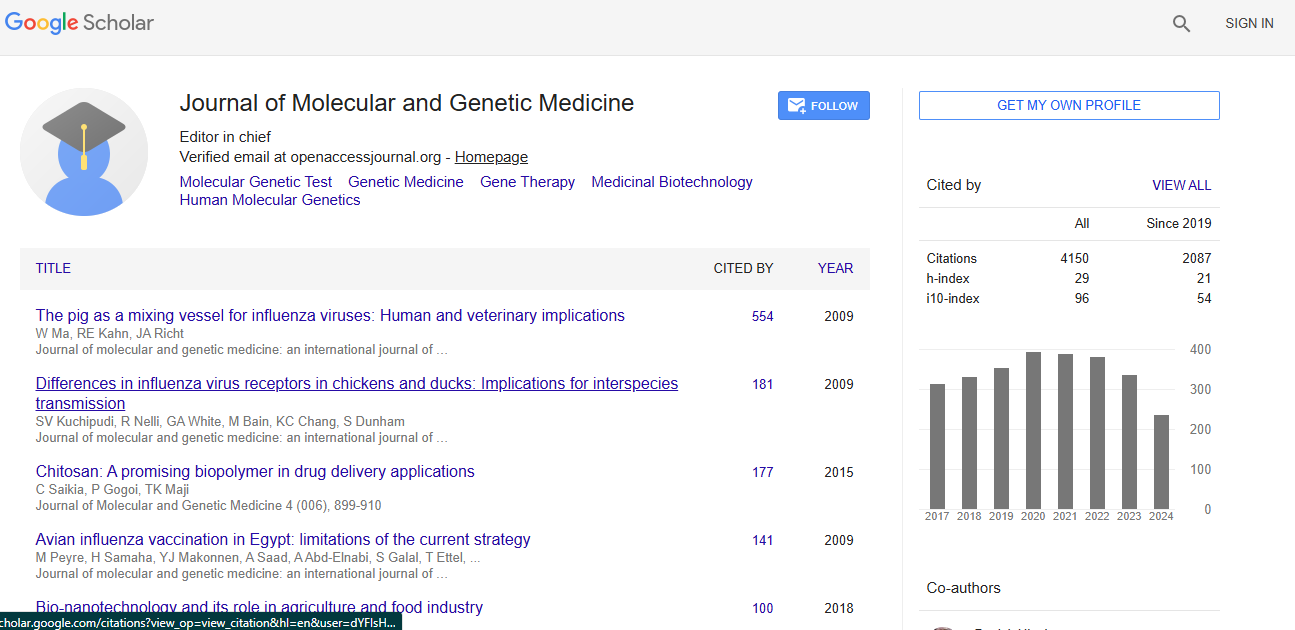
Molecular and Genetic Medicine received 3919 citations as per Google Scholar report