Opinion - (2025) Volume 12, Issue 1
Received: 02-Jan-2025, Manuscript No. bset-25-168433;
Editor assigned: 04-Jan-2025, Pre QC No. P-168433;
Reviewed: 18-Jan-2025, QC No. Q-168433;
Revised: 23-Jan-2025, Manuscript No. R-168433;
Published:
30-Jan-2025
, DOI: 10.37421/2952-8526.2025.12.238
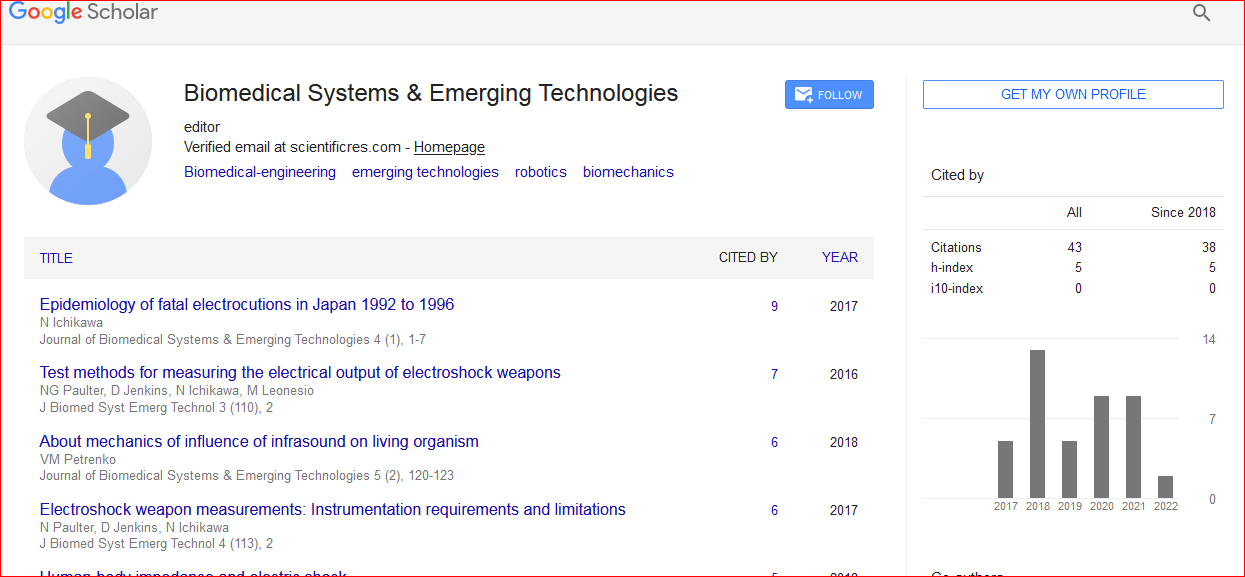
Citation: Dubois, Chloe. "Deep Learning Framework for Automatic Detection of Diabetic Retinopathy." J Biomed Syst Emerg Technol 12 (2025): 238.
Copyright: © 2025 Dubois C. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
A typical deep learning framework for DR detection is centered around convolutional neural networks (CNNs), which are particularly well-suited for processing high-resolution fundus photographs. These images are captured using specialized retinal cameras and provide a detailed view of the retinaâ??s vasculature and lesions such as microaneurysms, hemorrhages, exudates, and neovascularization. The CNN architecture consists of several layersâ??including convolutional layers for feature extraction, pooling layers for dimensionality reduction, and fully connected layers for classification. During training, the network learns to recognize DR-related patterns in fundus images by minimizing a loss function through backpropagation and gradient descent. The output layer typically assigns a probability or severity grade to each image, corresponding to standard DR classifications such as no DR, mild, moderate, severe, and proliferative DR.
The performance of a DL framework heavily depends on the quality, size, and diversity of its training data. Publicly available datasets such as the Kaggle EyePACS, Messidor, and IDRiD datasets have been widely used to train and benchmark DR detection models. These datasets consist of thousands of labeled fundus images, annotated by expert ophthalmologists. Data preprocessing plays a vital role in enhancing model performance. Common preprocessing steps include image resizing, contrast enhancement, normalization, and augmentation techniques such as flipping, rotation, and brightness adjustment. These procedures help the model generalize better and perform robustly under real-world conditions, where image quality may vary due to differences in acquisition equipment, lighting, and patient demographics [2].
To improve detection accuracy and interpretability, recent frameworks have incorporated techniques such as attention mechanisms, ensemble learning, and transfer learning. Attention mechanisms enable the model to focus on relevant regions of the retina such as areas showing early signs of damage thus enhancing diagnostic specificity. Ensemble learning combines multiple models to reduce variance and increase prediction stability. Transfer learning allows models pre-trained on large-scale datasets (e.g., ImageNet) to be fine-tuned for DR detection, significantly reducing training time and improving performance when labeled data is limited. Additionally, techniques like Grad-CAM (Gradient-weighted Class Activation Mapping) provide heatmaps that highlight the regions of the image influencing the modelâ??s prediction, thereby offering visual explanations for clinical review and validation.
Google Scholar Cross Ref Indexed at