Dipankar Sengupta1, 3, Didier Croes2, 3, Satyam Kapoor1, 4, Sonia Van Dooren2, 3, Maryse Bonduelle² and Ann Nowé1, 3
ScientificTracks Abstracts-Workshop: J Health Med Informat
As a part of the BRiDGEIris project, a clinical database CliniPhenome, has been developed that supports clinical and phenotypic annotation for patients. The project aims to develop a big data platform that can be used for sharing genomic and clinical data and support discovery studies in clinical genomics. A part of this goal was attained by the proposal of a generalized clinical schema design along with a merged ontology schema that provides cross-referencing possibilities. Also, introduction of the controlled vocabulary and data structure answers for the prevalent problem of plain text storage in the existing clinical databases, which causes impediment during data analysis. CliniPhenome not only supports the collection of patient data but also phenotypic and clinical annotation. Phenotypic annotation is supported by autogenously designed ontology that supports for Human Phenotype Ontology (HPO), Online Mendelian Inheritance in Man (OMIM) and Orphanet. Clinical annotation is currently supported by LOINC and SNOMED, with eventual assimilation of ICD-10 into it. It is a PHP based application with an easily operated interface that runs on a web browser and is facilitated by a MySQL database. A generalized schema design has been proposed, that ensures improved empathy among clinicians and researchers. Besides, it also features data migration utility that supports exchange of de-identified data in XML or JSON structure among the collaborators. In conclusion, CliniPhenome features streamlining of clinical workflow, efficient data entry and retrieval, improved diagnosis, cross-referencing of patient phenotype with clinical annotation, and sharing of de-identified patient data for research purposes. Acknowledgement: The authors acknowledge the support of the Bridge IRIS project funded by INNOVIRIS, Region de Bruxelles Capitale, Brussels, Belgium.
Dipankar Sengupta has completed his PhD in Bioinformatics from, Jaypee University of Information Technology, India. Currently, he is working as a Post doctoral researcher at COMO-Artificial Intelligence Lab, Vrije Universiteit Brussels, Belgium in BRiDGEIris project. Prior to this, he was working as Assistant Professor in Dept. of Bioinformatics & Biotechnology, Jaypee University of Information Technology, India. He aspires to unveil the intricacies of problem statements in life science and posses a passion to solve them with the aid of bioinformatics skills. His research interest broadly lies in the domain of Data mining, Database design & development, Algorithm design, Web interface development and Exploratory analysis. His primary research is focused on translational computing of clinical data with a considerable focus on temporal mining and auguring state of a disease for a patient. Currently, he is working on designing a Clinical-Phenomic Database and on development of machine learning approaches to connive comorbid patterns among the genomic variants with their associated clinical data.
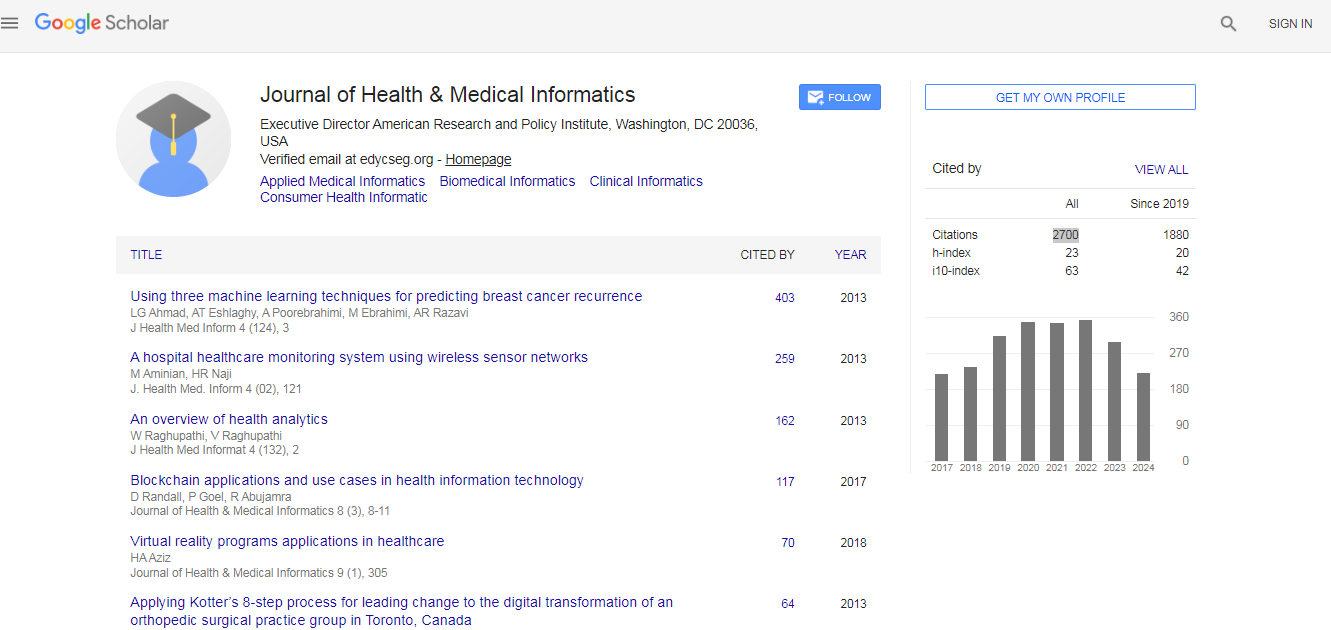
Journal of Health & Medical Informatics received 2700 citations as per Google Scholar report

 Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi 