Brief Report - (2025) Volume 19, Issue 6
Received: 01-Dec-2025, Manuscript No. jmgm-26-188398;
Editor assigned: 03-Dec-2025, Pre QC No. P-188398;
Reviewed: 17-Dec-2025, QC No. Q-188398;
Revised: 22-Dec-2025, Manuscript No. R-188398;
Published:
29-Dec-2025
, DOI: 10.37421/1747-0862.2025.19.754
Citation: Ionescu, Daniela. ”Multi-Omics: Accelerating Biomarker Discovery and Disease Insights.” J Mol Genet Med 19 (2025):754.
Copyright: © 2025 Ionescu D. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution and reproduction in any medium, provided the original author and source are credited.
Multi-omics analysis represents a powerful and transformative approach for biomarker discovery, offering an integrated perspective on biological systems by combining data from diverse molecular levels such as genomics, transcriptomics, proteomics, and metabolomics. This comprehensive view is instrumental in unraveling complex disease mechanisms and identifying novel biomarkers crucial for early diagnosis, prognosis, and therapeutic targeting. The inherent challenge lies in harmonizing and analyzing these disparate datasets to extract meaningful biological signals and rigorously validate potential biomarkers. Biomarker discovery through multi-omics analysis has emerged as a critical frontier in modern biomedical research, providing a more holistic understanding of biological processes and disease states than single-omic approaches [1].
Integrating transcriptomic and proteomic data provides unique insights into post-transcriptional regulation and identifies protein biomarkers that more directly reflect cellular function compared to mRNA levels. This dual approach is particularly vital for understanding diseases where gene expression patterns do not perfectly correlate with protein abundance, thereby leading to the identification of more robust biomarker candidates. Bridging the transcriptomic and proteomic gap is essential for advancing biomarker discovery in fields such as cancer research, where subtle regulatory mechanisms can significantly impact disease progression and patient outcomes [2].
Metabolomics offers a valuable snapshot of an organism's physiological state, rendering it highly relevant for discovering biomarkers associated with metabolic disorders and predicting responses to drug therapies. The strategic combination of metabolomic profiles with other omics data can illuminate how genetic or transcriptional alterations manifest at the metabolic level, furnishing functional insights and potential diagnostic markers. Multi-omics integration for biomarker discovery presents both significant challenges and exciting opportunities for uncovering novel diagnostic and prognostic tools [3].
The application of sophisticated computational tools, including machine learning and artificial intelligence, is indispensable for navigating the inherent complexity and high dimensionality of multi-omics data. These advanced computational methods are adept at discerning subtle patterns and correlations that may elude conventional statistical techniques, thereby accelerating both the discovery and validation processes for reliable biomarkers. Artificial intelligence for multi-omics data integration and biomarker discovery is revolutionizing how we interpret complex biological information [4].
Epigenomic data, encompassing information on DNA methylation and histone modifications, provides an additional layer of regulatory insights that can complement other omics datasets. These epigenetic modifications play a crucial role in influencing gene expression without altering the underlying DNA sequence, thereby offering unique perspectives into disease pathogenesis and the identification of potential epigenetic biomarkers. Multi-omics approaches for cancer biomarker discovery are increasingly incorporating epigenetic information to gain a more complete understanding of tumorigenesis [5].
The development and implementation of robust bioinformatic pipelines are paramount for the successful integration, analysis, and interpretation of multi-omics data. These pipelines must effectively address critical aspects such as data normalization, the management of batch effects, rigorous feature selection, and the identification of biologically relevant pathways and networks. Computational strategies for multi-omics data integration are continually evolving to meet the demands of complex biological studies [6].
Emerging single-cell multi-omics technologies represent a revolutionary advancement, enabling the simultaneous measurement of various molecular modalities within individual cells. This capability provides unprecedented resolution for understanding cellular heterogeneity and precisely identifying cell-type-specific biomarkers. Single-cell multi-omics is opening up a new frontier in biological research, allowing for a more granular examination of biological systems [7].
The discovery of circulating biomarkers, particularly those detected in liquid biopsies, holds immense promise for non-invasive disease monitoring and early detection. Multi-omics analysis of circulating nucleic acids, proteins, and metabolites can reveal disease-specific signatures with remarkable sensitivity and specificity. Liquid biopsy for precision oncology is rapidly advancing, offering new avenues for patient care and management [8].
Translating multi-omics biomarker discoveries into tangible clinical practice necessitates rigorous validation using independent patient cohorts and standardized assays. The seamless integration of multi-omics data into clinical decision-making workflows represents a critical step toward realizing the full potential of these groundbreaking findings. Translational multi-omics aims to bridge the gap from initial discovery to widespread clinical application [9].
The selection of an appropriate multi-omics integration strategy is of paramount importance and is dictated by the specific research question and the types of omics data being analyzed. Various integration approaches, including early, intermediate, or late integration, can be employed to uncover distinct biological insights and identify unique sets of biomarkers. A comprehensive review of multi-omics data integration methods highlights the diverse strategies available for biomarker discovery [10].
Multi-omics analysis offers a potent strategy for biomarker discovery by integrating data from genomics, transcriptomics, proteomics, and metabolomics, leading to a more profound understanding of biological systems and disease mechanisms. This approach facilitates the identification of novel biomarkers essential for early diagnosis, prognosis, and targeted therapies. A significant hurdle remains in harmonizing and analyzing these diverse datasets to extract meaningful biological signals and validate potential biomarkers. Biomarker discovery through multi-omics analysis is a rapidly evolving field with immense potential [1].
By integrating transcriptomic and proteomic data, researchers can uncover intricate post-transcriptional regulatory mechanisms and pinpoint protein biomarkers that offer a more direct reflection of cellular function than mRNA levels. This integrated approach is crucial for understanding disease states where gene expression does not perfectly align with protein abundance, thereby leading to the discovery of more robust biomarker candidates. The synergy between transcriptomic and proteomic data is vital for advancing biomarker discovery in areas like cancer research [2].
Metabolomics provides a valuable snapshot of an organism's physiological state, making it exceptionally relevant for identifying biomarkers associated with metabolic disorders and predicting therapeutic responses. Combining metabolomic profiles with other omics data allows for the elucidation of how genetic or transcriptional changes manifest at the metabolic level, providing crucial functional insights and potential diagnostic markers. The integration of metabolomics within multi-omics frameworks presents exciting opportunities for biomarker discovery [3].
The utilization of machine learning and artificial intelligence is indispensable for managing the complexity and high dimensionality characteristic of multi-omics data. These computational tools excel at identifying subtle patterns and correlations that traditional statistical methods might overlook, thus accelerating the discovery and validation of reliable biomarkers. The power of artificial intelligence is being harnessed to tackle the challenges of multi-omics data integration and biomarker identification [4].
Epigenomic data, including DNA methylation and histone modifications, contributes another critical layer of regulatory information that can complement other omics datasets. These epigenetic alterations can influence gene expression without altering the DNA sequence, providing unique insights into disease pathogenesis and the identification of novel epigenetic biomarkers. Multi-omics approaches are increasingly incorporating epigenomic data for comprehensive biomarker discovery, especially in complex diseases like cancer [5].
Establishing robust bioinformatic pipelines is fundamental to the successful integration and interpretation of multi-omics data. These pipelines must meticulously address data normalization, batch effect correction, feature selection, and the identification of biologically significant pathways and networks. The ongoing development of computational strategies for multi-omics data integration is essential for unlocking the full potential of these complex datasets [6].
Single-cell multi-omics technologies represent a groundbreaking advancement, enabling the simultaneous measurement of various molecular modalities within individual cells. This provides unparalleled resolution for dissecting cellular heterogeneity and identifying cell-type-specific biomarkers. The emergence of single-cell multi-omics is ushering in a new era of biological exploration and discovery [7].
The discovery of circulating biomarkers, such as those found in liquid biopsies, offers a promising avenue for non-invasive disease monitoring and early detection. Multi-omics analysis of circulating nucleic acids, proteins, and metabolites can reveal disease-specific signatures with high sensitivity and specificity. The field of liquid biopsy for precision oncology is rapidly expanding, with multi-omics playing a central role [8].
Translating multi-omics biomarker discoveries into clinical practice requires stringent validation using independent patient cohorts and standardized assays. The effective integration of multi-omics data into clinical decision-making workflows is a critical step toward realizing the full clinical utility of these findings. The translational aspect of multi-omics research is key to bridging the gap between discovery and application [9].
The selection of an appropriate multi-omics integration strategy is critically important and depends heavily on the specific research question and the types of omics data being analyzed. Different strategies, such as early, intermediate, or late integration, can be employed to uncover distinct biological insights and identify unique sets of biomarkers. A thorough understanding of these integration methods is crucial for successful biomarker discovery endeavors [10].
Multi-omics analysis integrates data from genomics, transcriptomics, proteomics, and metabolomics to enhance biomarker discovery for improved disease diagnosis, prognosis, and treatment. Challenges include data harmonization and analysis. Combining transcriptomics and proteomics reveals post-transcriptional regulation and protein biomarkers. Metabolomics offers insights into physiological states and metabolic disorders. Machine learning and AI are essential for analyzing complex multi-omics data. Epigenomic data adds another layer of regulatory information. Robust bioinformatic pipelines are crucial for data integration and interpretation. Single-cell multi-omics provides high-resolution cellular insights. Circulating biomarkers from liquid biopsies enable non-invasive monitoring. Translating discoveries requires rigorous validation and clinical integration. The choice of integration strategy is vital for uncovering biological insights and identifying biomarkers.
None
None
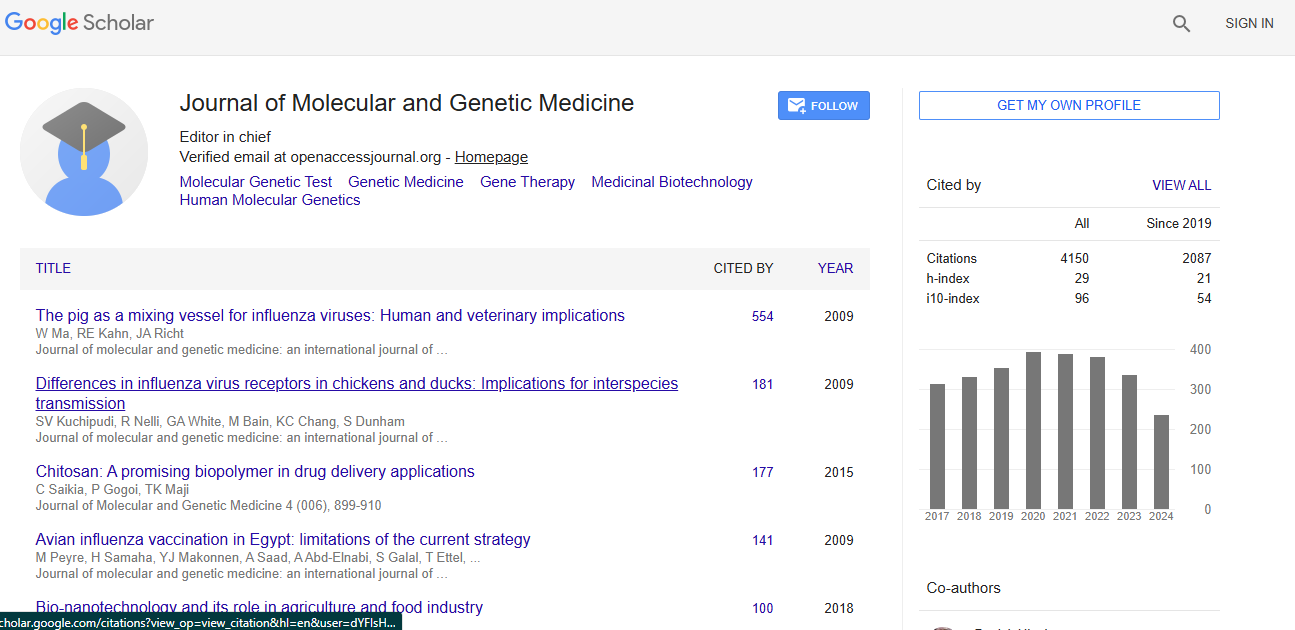
Molecular and Genetic Medicine received 3919 citations as per Google Scholar report