Brief Report - (2025) Volume 16, Issue 4
Received: 01-Jul-2025, Manuscript No. jhmi-26-178850;
Editor assigned: 03-Jul-2025, Pre QC No. P-178850;
Reviewed: 17-Jul-2025, QC No. Q-178850;
Revised: 22-Jul-2025, Manuscript No. R-178850;
Published:
29-Jul-2025
, DOI: 10.37421/2157-7420.2025.16.599
Citation: Salah, Youssef A. Ben. ”Genomic Data Integration for Precision Medicine: Challenges and Solutions.” J Health Med Informat 16 (2025):599.
Copyright: © 2025 Salah B. A. Youssef This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution and reproduction in any medium, provided the original author and source are credited.
The integration of genomic data into clinical informatics workflows represents a paradigm shift towards realizing precision medicine, enabling highly personalized healthcare approaches tailored to an individual's genetic makeup. This process necessitates the development of robust data standards, secure storage solutions, and sophisticated analytical pipelines that can effectively handle complex genomic information alongside traditional clinical data. Key challenges inherent in this integration include achieving interoperability between disparate systems, ensuring stringent data privacy, and equipping clinicians with the necessary training to interpret and act upon genomic insights for improved patient care. Successful integration is poised to empower more personalized diagnoses, facilitate the selection of targeted therapies, and promote proactive disease management strategies by leveraging the wealth of information contained within an individual's genome. This advancement requires a comprehensive framework that addresses both the technical and practical aspects of genomic data utilization in a clinical setting, paving the way for a more effective and individualized approach to healthcare. The evolution of electronic health records (EHRs) presents a crucial avenue for incorporating genomic variants, but this requires standardized terminologies, such as HGVS, and ontologies to ensure data consistency and facilitate its seamless integration into clinical decision support systems. Furthermore, the ethical dimensions surrounding patient consent and data ownership are paramount when dealing with sensitive genomic information. The development of a scalable informatics infrastructure is fundamental for managing the ever-increasing volume of large-scale genomic datasets generated within healthcare systems. Such an infrastructure must encompass efficient data ingestion, rigorous quality control, accurate variant calling, and comprehensive annotation processes, often leveraging cloud computing and containerization for optimal processing power and scalability. The creation of a unified patient genomic profile, accessible to various healthcare stakeholders, is a critical objective, necessitating the development of robust data governance models that guarantee data quality, security, and appropriate access controls, while simultaneously facilitating both research and clinical applications. The integration of germline and somatic genomic data, particularly in the field of oncology, offers profound benefits for precision treatment strategies. By combining these distinct data types, clinicians can achieve more precise diagnoses, identify actionable mutations, and select highly targeted therapies, thereby significantly improving patient outcomes. Advanced bioinformatics tools are indispensable for the accurate interpretation of these integrated datasets, ensuring that clinicians can derive meaningful insights for treatment planning. Machine learning algorithms are increasingly being explored for their potential to analyze complex genomic data within clinical informatics systems, offering powerful capabilities for disease risk prediction, variant interpretation, and patient stratification for clinical trials. The emphasis on interpretable AI models and validated datasets is crucial for their successful clinical adoption and trust. The practical implementation of genomic data integration within a hospital setting requires a clear outline of best practices, encompassing data collection, standardization, and the development of intuitive workflows that enable clinicians to readily access and utilize genomic information at the point of care. This underscores the vital importance of interdisciplinary collaboration among bioinformaticians, clinicians, and IT professionals to bridge the gap between genomic discovery and clinical utility. The ongoing evolution of data standards, such as FHIR, is essential for accommodating the complexities of genomic data within health information systems. Addressing the challenges of representing intricate genomic information, including VCF files and variant annotations, in a standardized and interoperable manner is key to facilitating its seamless exchange and utilization across diverse healthcare platforms. Finally, the robust processing and interpretation of raw genomic sequencing data for clinical applications rely heavily on sophisticated bioinformatics pipelines. These pipelines, encompassing workflows for variant calling, annotation, and functional impact assessment, must prioritize accuracy, reproducibility, and computational efficiency to support timely and reliable clinical decision-making. [1].
The integration of genomic data into clinical informatics workflows is paramount for the successful realization of precision medicine, a transformative approach to healthcare that tailors medical treatment to the individual characteristics of each patient. This integration involves the meticulous development of standardized data formats, the implementation of secure and robust data storage solutions, and the creation of sophisticated analytical pipelines capable of processing complex genomic information in conjunction with traditional clinical data. A significant hurdle in this process lies in achieving interoperability between diverse healthcare systems and genomic data repositories, alongside addressing critical concerns related to data privacy and ensuring that clinicians are adequately trained to interpret and effectively act upon the insights derived from genomic analyses. The successful assimilation of genomic data into clinical practice promises to revolutionize patient care by enabling more precise diagnoses, guiding the selection of targeted therapies, and facilitating proactive disease management strategies. This requires a multifaceted approach that considers the technical infrastructure, ethical implications, and educational needs of healthcare professionals. This study explores the intricate technical and ethical considerations that arise when incorporating variant data into electronic health records (EHRs), emphasizing the critical need for standardized terminologies, such as the Human Genome Variation Society (HGVS) nomenclature, and comprehensive ontologies. These standards are essential for ensuring data consistency, facilitating accurate data retrieval, and enabling the effective integration of genomic information into clinical decision support systems. The authors further underscore the paramount importance of establishing clear patient consent processes and defining patient data ownership in the context of managing sensitive genomic information. The development and implementation of a scalable informatics infrastructure are fundamental to effectively managing the ever-increasing volume and complexity of large-scale genomic datasets generated within healthcare settings. This infrastructure must support efficient data ingestion, rigorous quality control measures, accurate variant calling, and comprehensive annotation processes, often leveraging the power of cloud computing and containerization technologies for enhanced processing capabilities and flexibility. The endeavor to create a unified patient genomic profile that can be readily accessed and utilized by various healthcare stakeholders presents both challenges and opportunities. This necessitates the development of robust data governance models designed to ensure the highest standards of data quality, security, and appropriate access controls, while simultaneously fostering an environment conducive to research and clinical application. The integration of germline and somatic genomic data plays a pivotal role in advancing precision oncology, offering significant benefits for cancer treatment. Combining these distinct genomic datasets enables more precise diagnoses, facilitates the identification of actionable mutations, and guides the selection of highly targeted therapies, ultimately leading to improved patient outcomes. The article highlights the indispensable role of sophisticated bioinformatics tools for accurately interpreting these integrated datasets and translating them into actionable clinical insights. The potential of machine learning algorithms to analyze complex genomic data within clinical informatics systems is a rapidly evolving area of research, offering powerful capabilities for disease risk prediction, variant interpretation, and patient stratification for clinical trials. A crucial aspect of this research is the emphasis on developing interpretable AI models and utilizing validated datasets to ensure their reliability and foster clinical adoption. The practical implementation of genomic data integration in hospital workflows demands a clear understanding of best practices for data collection, standardization, and the creation of user-friendly workflows that empower clinicians to access and utilize genomic information effectively at the point of care. This underscores the critical need for strong interdisciplinary collaboration among bioinformaticians, clinicians, and IT professionals to bridge the gap between genomic discovery and clinical application. The evolution of data standards, exemplified by the development of standards like FHIR (Fast Healthcare Interoperability Resources), is essential for enabling the seamless accommodation of genomic data within health information systems. The challenges associated with representing complex genomic information, including variant call format (VCF) files and variant annotations, in a standardized and interoperable manner are being actively addressed to facilitate data exchange and utilization across diverse platforms. The accurate and efficient processing and interpretation of raw genomic sequencing data for clinical applications are critically dependent on the development and deployment of robust bioinformatics pipelines. These pipelines, encompassing essential workflows for variant calling, annotation, and functional impact assessment, must be designed with a strong emphasis on accuracy, reproducibility, and computational efficiency to support timely and reliable clinical decision-making. [1].
The integration of genomic data into clinical informatics is crucial for precision medicine, requiring standardized data, secure storage, and analytical pipelines. Key challenges include interoperability, privacy, and clinician training. Successful integration leads to personalized diagnoses and targeted therapies. Incorporating variant data into EHRs necessitates standardized terminologies and ethical considerations like consent and data ownership. Scalable informatics infrastructure is needed for large-scale genomic data management, using cloud computing and containerization. A unified patient genomic profile requires robust data governance for quality, security, and access. Integrating germline and somatic genomic data, especially in oncology, improves diagnosis and targeted therapy selection. Machine learning offers potential for analyzing genomic data for risk prediction and patient stratification, with a focus on interpretable AI. Practical implementation in hospitals involves best practices for data handling and clinician workflows, emphasizing interdisciplinary collaboration. Evolving data standards like FHIR are key for genomic data interoperability. Bioinformatics pipelines are essential for accurate and efficient processing of genomic sequencing data for clinical interpretation.
None
None
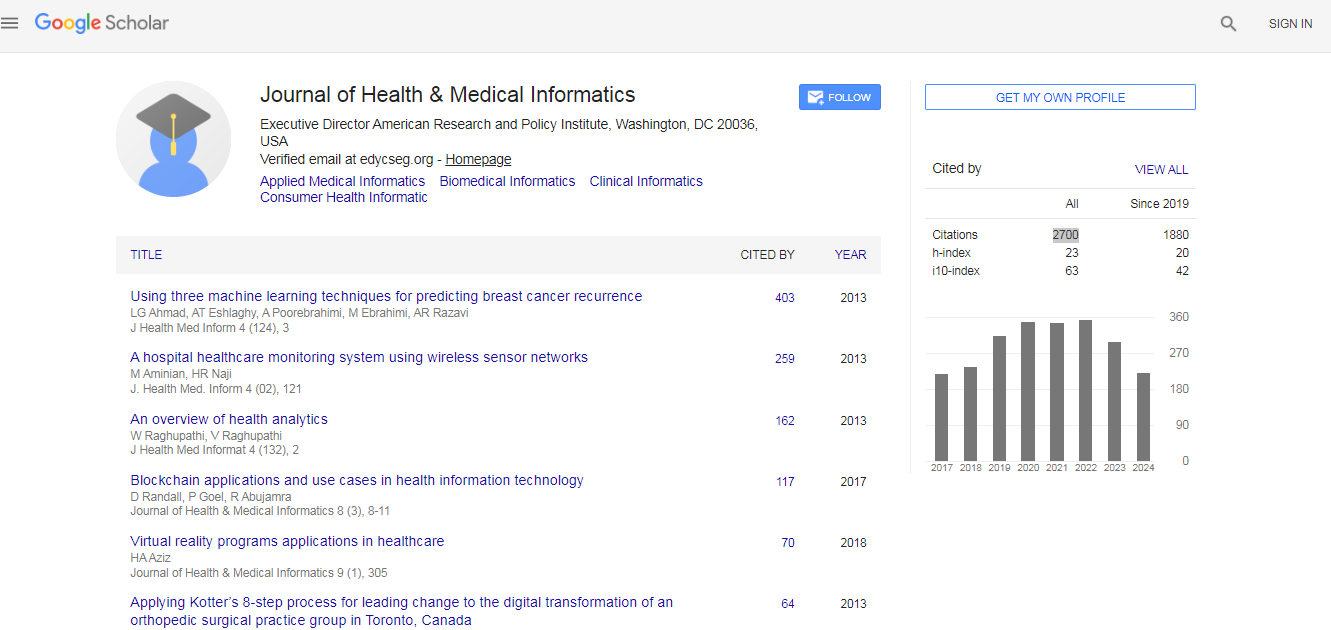
Journal of Health & Medical Informatics received 2700 citations as per Google Scholar report