Mini Review - (2023) Volume 14, Issue 5
Received: 02-Oct-2023, Manuscript No. gjto-23-119439;
Editor assigned: 04-Oct-2023, Pre QC No. P-119439;
Reviewed: 17-Oct-2023, QC No. Q-119439;
Revised: 23-Oct-2023, Manuscript No. R-119439;
Published:
30-Oct-2023
, DOI: 10.37421/2229-8711.2023.14.352
Citation: Cloirec, Helmer. “Challenges in Large-Scale Optimization: Handling Big Data and High Dimensionality.” Global J Technol Optim 14 (2023): 352.
Copyright: © 2023 Cloirec H. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
In an era dominated by the digital revolution, the process of large-scale optimization has taken center stage across various domains. As the volume of data continues to grow exponentially and the dimensionality of problems escalates, handling big data and high dimensionality has become a formidable challenge. This article delves into the intricacies of large-scale optimization, exploring the key challenges it faces in dealing with big data and high dimensionality. We discuss the significance of these challenges, potential solutions and their implications across diverse fields.
Large scale optimization • High dimensionality • Computational complexity • Data preprocessing • Machine learning • Data science
Large-scale optimization is at the heart of many critical applications in fields such as machine learning, finance, engineering and data science. It is the process of finding the best solution from a vast set of possible options, making it vital for decision-making and problem-solving. However, as the world's data grows at an unprecedented pace, the problems associated with big data and high dimensionality has put substantial strain on large-scale optimization techniques. One of the most significant challenges is the computational complexity that arises when dealing with massive datasets. The sheer volume of data can make traditional optimization methods infeasible, demanding more efficient algorithms to scale appropriately. The quality of data can significantly impact the optimization process. Inaccurate, noisy, or incomplete data can lead to suboptimal results. Data preprocessing, which includes data cleaning, dimensionality reduction and feature selection, is crucial for mitigating these issues.
Scalability concerns how well optimization algorithms perform as data sizes increase. Ensuring that algorithms can handle larger datasets without exponential increases in computation time is essential for real-world applications. The curse of dimensionality refers to the exponential growth in data points' distribution as the number of dimensions increases. In highdimensional spaces, distances between data points become less informative, making optimization problems more challenging. Many high-dimensional datasets are sparse, meaning they contain a vast number of zero or nearzero values. Traditional optimization methods may not effectively exploit this sparsity, leading to inefficient solutions. High dimensionality can lead to overfitting in machine learning models, where models perform exceptionally well on training data but generalize poorly to unseen data. Overcoming this challenge requires careful feature selection and regularization techniques [1,2].
Parallel computing and distributed systems can help alleviate the computational burden associated with big data. Algorithms can be designed to process data in parallel, exploiting the power of multiple processing units or distributed clusters. In cases where data arrives continuously or is too vast to fit into memory, streaming and online learning techniques can be employed. These methods enable continuous model updates as new data becomes available. Techniques such as Principal Component Analysis (PCA) and feature selection can help reduce dimensionality while preserving essential information. This not only simplifies the optimization process but also enhances the interpretability of results. In machine learning, regularization methods like L1 and L2 regularization can prevent overfitting in high-dimensional spaces. These techniques encourage models to be simpler by adding penalties to the optimization objective [3].
Large-scale optimization plays a pivotal role in modern data-driven applications, but it faces formidable challenges when dealing with big data and high dimensionality. As the volume and complexity of data continue to grow, addressing these challenges becomes even more critical. Researchers and practitioners must innovate and adapt by developing more efficient algorithms, exploring novel data preprocessing techniques and leveraging parallel computing to tackle the unique issues posed by big data and high dimensionality. Only through such efforts can large-scale optimization continue to provide valuable solutions across a wide range of domains.
Machine learning models, such as deep neural networks, often grapple with high-dimensional data. Overcoming these challenges is critical for the development of more accurate and efficient models. Advanced optimization techniques are essential for training deep learning models on large datasets. In financial markets, real-time decision-making is crucial and big data analysis is paramount. Optimizing investment portfolios, risk management and fraud detection all require large-scale optimization, demanding efficient algorithms capable of handling vast datasets. Engineers face optimization problems in designing structures, systems and processes [4,5].
Data scientists rely heavily on optimization techniques for model selection, hyperparameter tuning and feature engineering. Effective optimization can significantly improve the quality and performance of data-driven models. In healthcare, large-scale optimization is used for treatment planning, drug discovery and patient care optimization. The challenges of big data and high dimensionality must be addressed to enhance the precision of medical decision-making. Continued research into developing novel optimization algorithms that are scalable, efficient and suitable for high-dimensional spaces is essential. Techniques like stochastic gradient descent and genetic algorithms are promising candidates. The evolution of hardware, such as Graphics Processing Units (GPUs) and specialized hardware for AI and machine learning, has the potential to accelerate large-scale optimization by providing more computational power [6].
Collaboration between researchers from various fields, including mathematics, computer science and domain-specific experts, is critical for finding innovative solutions to complex optimization challenges. Preparing the next generation of data scientists and engineers with the skills to navigate large-scale optimization problems will be crucial. Academic programs and professional training should focus on these challenges. The challenges posed by big data and high dimensionality in large-scale optimization are significant but not insurmountable. With ongoing research and interdisciplinary collaboration, it is possible to develop efficient algorithms and data preprocessing techniques to handle the ever-expanding world of data. As we continue to embrace the data-driven age, mastering large-scale optimization remains a fundamental component of innovation and progress across numerous domains.
We thank the anonymous reviewers for their constructive criticisms of the manuscript.
The author declares there is no conflict of interest associated with this manuscript.
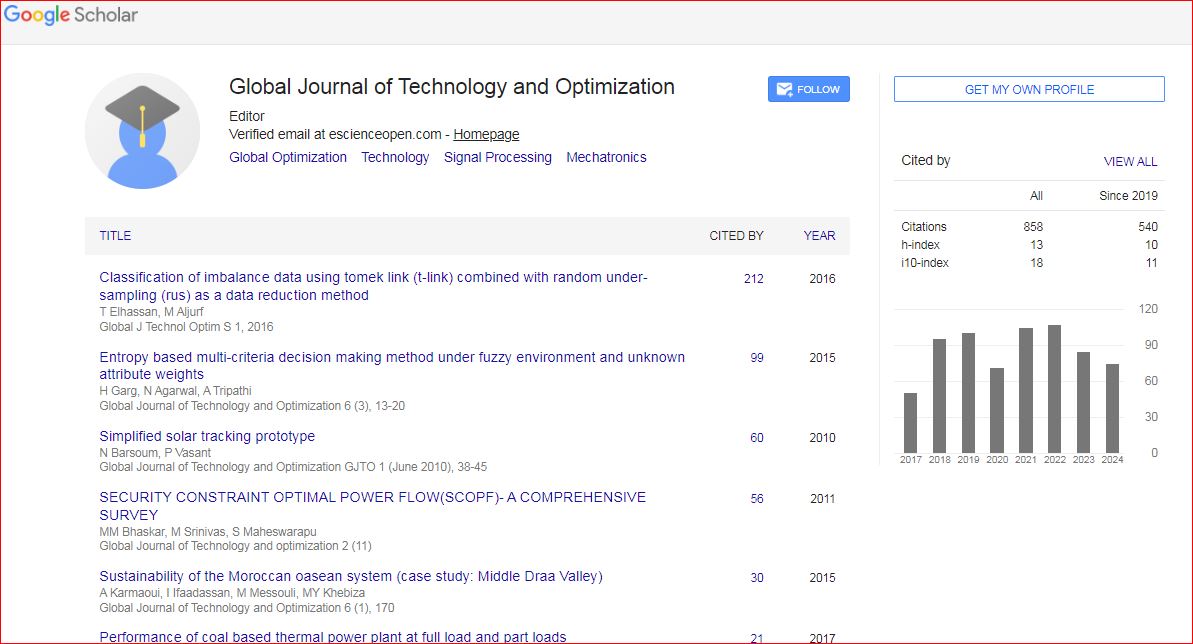
Global Journal of Technology and Optimization received 847 citations as per Google Scholar report