Perspective - (2025) Volume 10, Issue 3
Received: 02-Jun-2025, Manuscript No. jcct-26-183216;
Editor assigned: 04-Jun-2025, Pre QC No. P-183216;
Reviewed: 18-Jun-2025, QC No. Q-183216;
Revised: 23-Jun-2025, Manuscript No. R-183216;
Published:
30-Jun-2025
, DOI: 10.37421/2577-0535.2025.9.314
Citation: Muller, Thomas. ”Advancing Cancer Trial Statistics: Innovations for Oncology.” J Cancer Clin Trials 10 (2025):314.
Copyright: © 2025 Muller T. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution and reproduction in any medium, provided the original author and source are credited.
The landscape of cancer clinical trials is undergoing a profound transformation, driven by significant advancements in statistical methodologies. These innovations are crucial for increasing the efficiency and accuracy of research, ultimately accelerating the development of novel cancer therapies. Early investigations into these statistical tools have laid the groundwork for more sophisticated approaches to trial design and analysis. Recent developments have highlighted the power of adaptive trial designs, which permit pre-specified modifications based on accumulating data. This flexibility is particularly valuable in oncology, where the rapid pace of scientific discovery demands agile research frameworks. Such designs can lead to increased statistical power and reduced sample sizes, enabling faster decision-making and a more efficient allocation of resources. Parallel to advances in trial design, Bayesian statistical methods have gained prominence in cancer research. Unlike traditional frequentist approaches, Bayesian inference offers more intuitive probability statements about treatment effects and can effectively incorporate prior knowledge. This is especially beneficial in early-phase trials and studies involving rare cancers, where data may be limited. Furthermore, the burgeoning field of machine learning (ML) is presenting unprecedented opportunities for analyzing complex cancer clinical trial data. ML techniques are being employed for predicting treatment responses, identifying potential biomarkers, and optimizing patient recruitment strategies. The potential to uncover intricate patterns and personalize treatment approaches is immense, although challenges related to interpretability and validation remain. Specific trial designs, such as multi-arm, multi-stage (MAMS) trials, are also benefiting from statistical refinement. These designs facilitate the efficient comparison of multiple treatments and allow for the early discontinuation of ineffective treatment arms, thereby optimizing resource utilization and patient participation in promising studies. Addressing the pervasive issue of missing data is another critical area of statistical focus in cancer clinical trials. Robust imputation methods and sensitivity analyses are essential to ensure the integrity and reliability of trial results. The careful selection of techniques to handle missing information can prevent biased estimates and strengthen the validity of conclusions drawn from the data. The integration of real-world data (RWD) and real-world evidence (RWE) into cancer clinical trials represents a significant paradigm shift. RWD can inform trial design, supplement control arms, and enhance post-market surveillance. Statistical methods are being developed to effectively bridge RWD with traditional clinical trial evidence, offering a more comprehensive understanding of treatment efficacy and safety. Biomarker-driven cancer trials present unique statistical challenges and opportunities. Methods for identifying patient subgroups, handling multiple endpoints, and utilizing statistical learning for biomarker discovery are crucial for advancing precision oncology. Robust statistical frameworks are essential to support the personalized treatment strategies that are becoming increasingly central to cancer care. The analysis of immuno-oncology therapies, with their complex immune-related endpoints, requires specialized statistical approaches. Innovations in adaptive designs for optimizing dose and schedule, coupled with statistical methods tailored to these unique characteristics, are vital for the successful development of these promising treatments. Finally, the application of causal inference methods to analyze both clinical trial and real-world data is gaining traction. Techniques such as propensity score matching and instrumental variables help to estimate treatment effects more reliably in the presence of confounding factors, providing stronger evidence from non-randomized studies and complementing findings from randomized controlled trials.
Statistical methodologies are at the forefront of advancing cancer clinical trials, offering sophisticated tools to enhance research efficiency and accuracy. The review of recent advancements highlights a paradigm shift in how trials are designed and analyzed, moving towards more dynamic and data-driven approaches. Innovations in statistical techniques are not only improving the estimation of treatment effects but also accelerating the overall pace of drug development for cancer therapies. Adaptive clinical trial designs represent a significant leap forward, allowing for modifications based on interim data. This adaptability is crucial in oncology, where early indications of efficacy or futility can lead to rapid adjustments, saving time and resources. The benefits extend to increased statistical power and reduced sample sizes, making research more efficient and patient-centric. Bayesian statistical methods are increasingly being adopted for their ability to provide intuitive probabilistic interpretations of treatment effects. Their capacity to incorporate prior information is particularly valuable in cancer research, where existing knowledge can guide the interpretation of new data, especially in trials with limited patient populations or rare disease contexts. The integration of machine learning (ML) into cancer clinical trial analysis promises to unlock new insights from vast datasets. ML algorithms can identify complex predictive patterns, aiding in patient stratification and the discovery of novel biomarkers. This capability is fundamental to the advancement of personalized medicine in oncology. Specialized trial designs like multi-arm, multi-stage (MAMS) trials are also being optimized through statistical advancements. These designs enable the efficient evaluation of multiple treatment options simultaneously, allowing for the early termination of non-performing arms and a quicker focus on promising therapies. Handling missing data is a persistent challenge in clinical trials, and statistical methods provide essential solutions. Various imputation techniques and sensitivity analyses are employed to ensure that incomplete data does not compromise the integrity of the trial results, leading to more reliable conclusions. The incorporation of real-world data (RWD) and real-world evidence (RWE) into clinical trial design and analysis marks a pivotal development. RWD can enrich trial datasets, inform the design of control arms, and provide crucial information for post-market surveillance, offering a more comprehensive understanding of treatment outcomes in diverse patient populations. Biomarker-driven trials necessitate advanced statistical approaches to effectively identify patient subgroups and discover predictive biomarkers. These methods are essential for realizing the promise of precision oncology, ensuring that treatments are targeted to the patients most likely to benefit. In the realm of immuno-oncology, statistical innovations are key to navigating the complexities of immune-related endpoints and optimizing adaptive designs for dose and schedule. These tailored statistical approaches are vital for understanding the unique mechanisms of action of immunotherapies. Causal inference methods are becoming increasingly important for analyzing observational data and providing a deeper understanding of treatment effects in real-world settings. Techniques that account for confounding factors offer a more robust estimation of treatment efficacy, complementing the findings from randomized controlled trials.
This compilation of research explores the cutting-edge statistical methodologies transforming cancer clinical trials. It covers advancements in adaptive trial designs, Bayesian approaches, and machine learning for predictive modeling and patient stratification. The focus is on enhancing trial efficiency, improving treatment effect estimation, and accelerating the development of novel cancer therapies. Specific topics include multi-arm, multi-stage trials, handling missing data, integrating real-world data, analyzing biomarker-driven studies, and statistical innovations for immuno-oncology. Causal inference methods for real-world data analysis are also discussed, highlighting the continuous evolution of statistical tools to support precision oncology and optimize therapeutic development.
None
None
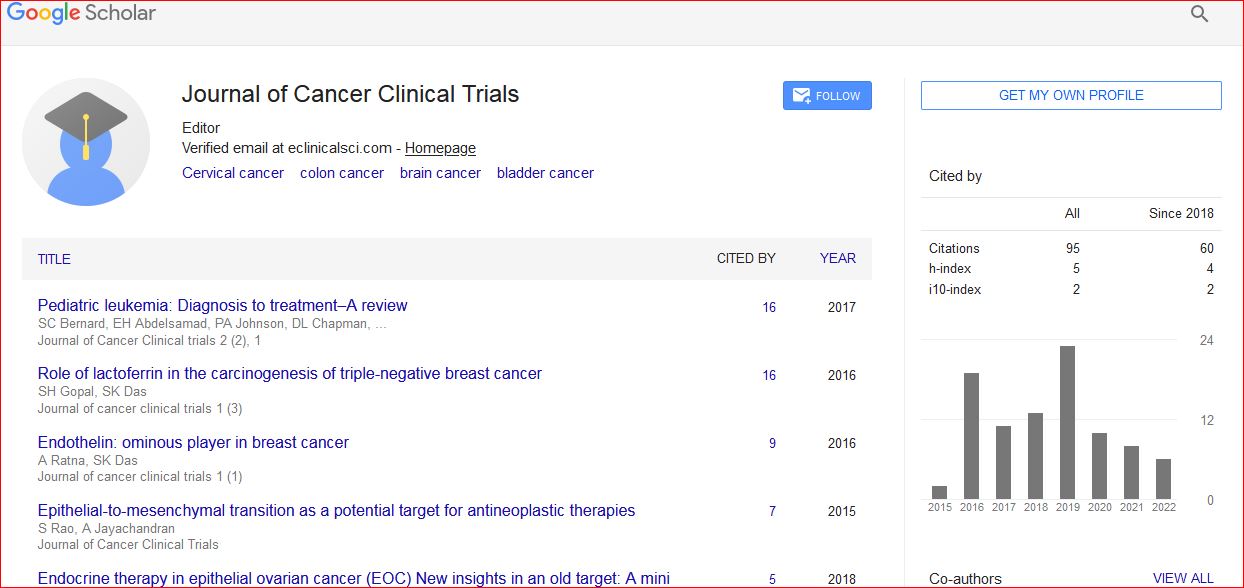
Journal of Cancer Clinical Trials received 95 citations as per Google Scholar report