Neda Navidi
The main focus of this talk is "human-AI teaming", specifically the mode of "human-AI collaboration" where humans and AIRL-based agents accomplish tasks together in a multi-agent system. Therefore, the objective cannot be achieved by just a lone human or agent, and the responsibilities in the environment are partitioned and/or shared between humans and agents. Collaborative multi-agent reinforcement learning (MARL) as a specific category of reinforcement learning (RL) provides effective results with agents learning from their observations, received rewards, and internal interactions between agents. However, centralized learning methods with a joint global policy in a highly dynamic environment present unique challenges in dealing with large amounts of information. This study proposes two innovative solutions to address the complexities of a collaboration between human and multiple RL-based agents (referred to hereafter as “Human-MARL teaming”) where the goals pursued cannot be achieved by a human alone or agents alone. The first innovation is the introduction of a new open-source MARL framework, called COGMENT, to unite humans and agents in real-time complex dynamic systems and efficiently leverage their interactions as a source of learning. The second innovation is our proposal of a new hybrid MARL method, named Dueling Double Deep Q learning MADDPG (D3-MADDPG) to allow agents to train decentralized policies parallelly in a joint centralized policy. This method can solve the overestimation problem in Q-learning methods of value-based MARL. We demonstrate these innovations by using a designed real-time environment with unmanned aerial vehicles driven by RL agents, collaborating with a human to fight fires. The team of RL agent drones autonomously looks for fire seats and the human pilot douses the fires. The results of this study show that the proposed collaborative paradigm and the open-source framework leads to significant reductions in both human effort and exploration costs. Also, the results of the proposed hybrid MARL method shows that it effectively improves the learning process to achieve more reliable Q-values for each action, by decoupling the estimation between state value and advantage value.
PDFShare this article
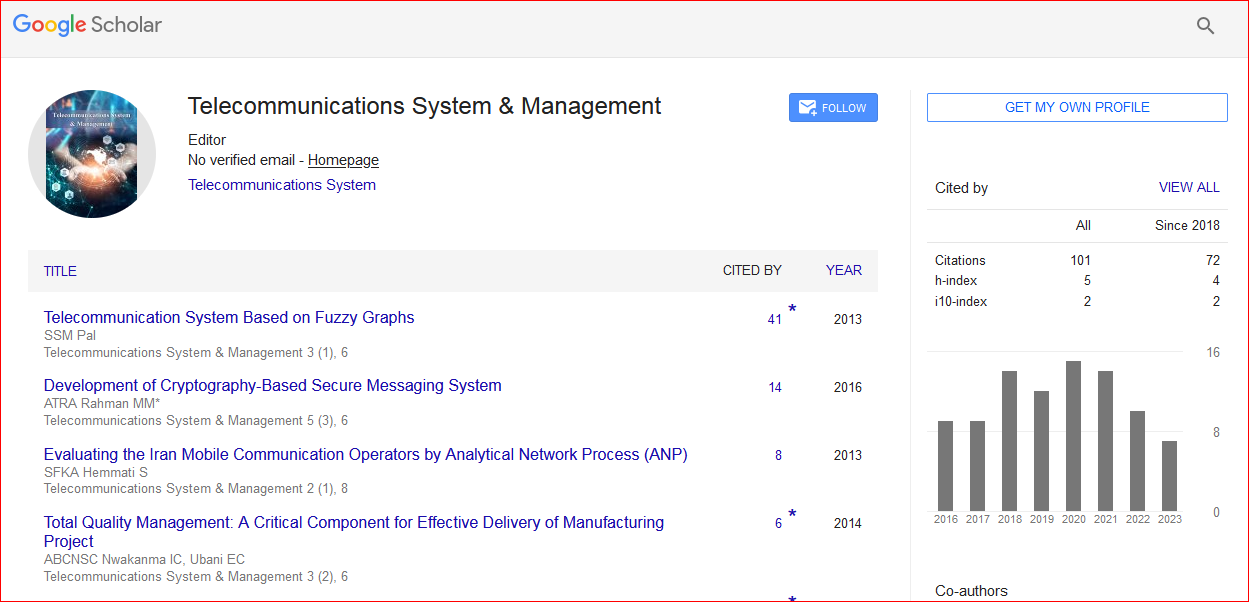
Telecommunications System & Management received 109 citations as per Google Scholar report