Short Communication - (2025) Volume 13, Issue 5
Received: 01-Oct-2025, Manuscript No. JCMG-26-185554;
Editor assigned: 03-Oct-2025, Pre QC No. P-185554;
Reviewed: 17-Oct-2025, QC No. Q-185554;
Revised: 22-Oct-2025, Manuscript No. R-185554;
Published:
29-Oct-2025
, DOI: 10.37421/2472-128X.2025.13.366
Citation: Al-Zahra, Fatima. ”Variant Interpretation Challenges and AI Solutions.” J Clin Med Genomics 13 (2025):366.
Copyright: © 2025 Al-Zahra F. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution and reproduction in any medium, provided the original author and source are credited.
Interpreting variants in clinical genomics is a critical yet challenging endeavor, essential for diagnosing genetic disorders and guiding patient treatment strategies. A significant hurdle in this process is the classification of variants of uncertain significance (VUS), which often lack sufficient evidence to definitively determine their pathogenicity. This complexity underscores the necessity for developing robust, standardized, and reproducible workflows to ensure accurate and consistent interpretation across different clinical settings. Machine learning and artificial intelligence (AI) are rapidly emerging as powerful tools capable of aiding in variant classification. By analyzing vast datasets and identifying intricate patterns that may elude human analysis, these computational approaches offer a promising avenue for improving the efficiency and accuracy of genomic interpretation. However, the integration of AI into clinical genomics is not without its challenges. Paramount among these are ethical considerations, including data privacy and the requirement for transparent AI models. Ensuring that these powerful tools are used responsibly and ethically is crucial for maintaining patient trust and upholding the integrity of clinical genomic testing. Collaborative efforts and the development of comprehensive databases are also essential components for advancing variant interpretation. Sharing and curating variant information across institutions and research groups can significantly enhance diagnostic yields and ultimately improve patient outcomes by pooling collective knowledge and resources. The exponential growth of next-generation sequencing data has significantly amplified the challenge of variant interpretation. As the volume of genomic information expands, establishing clear guidelines and standardized methodologies for variant prioritization and classification becomes increasingly vital for navigating this data deluge. Integrating diverse data sources is key to resolving variants of uncertain significance. This includes incorporating findings from functional studies, population frequencies, and detailed clinical phenotypes to build a more comprehensive picture of a variant's potential impact. The development of sophisticated bioinformatics tools and well-established databases, such as ClinVar and gnomAD, plays an indispensable role in this interpretive process. These resources provide essential reference points for assessing variant frequency and potential pathogenicity. Interpreting rare genetic variants is inherently a complex process that demands a multidisciplinary approach. Effective collaboration between clinical geneticists, bioinformaticians, and laboratory scientists is crucial for pooling expertise and achieving accurate classifications. Leveraging advancements in functional genomics and in silico prediction tools can provide additional, crucial evidence for variant pathogenicity. These tools supplement traditional methods by offering deeper insights into a variant's functional consequences. While frameworks like the ACMG/AMP guidelines offer a structured approach to variant classification, their application to novel variants often requires expert judgment and iterative refinement. This highlights the ongoing need for continuous development and adaptation of interpretive strategies.
The interpretation of variants within clinical genomics is paramount for the accurate diagnosis of genetic disorders and the effective guidance of treatment plans for patients. A significant impediment in this field is the classification of variants of uncertain significance (VUS), which are characterized by a lack of sufficient evidence to establish their pathogenicity. This necessitates the development and implementation of robust, standardized, and reproducible workflows to ensure consistent and reliable interpretation of genomic data across diverse clinical settings. In recent years, machine learning and artificial intelligence (AI) have emerged as powerful instrumental tools to assist in the complex process of variant classification. These advanced computational approaches are capable of analyzing extensive datasets, identifying subtle yet significant patterns, and potentially accelerating the diagnostic process. However, the integration of AI into clinical genomics presents several critical considerations that must be carefully addressed. Ethical concerns, including the safeguarding of patient data privacy and the imperative for transparent and interpretable AI models, are of utmost importance to ensure responsible deployment and maintain patient trust. Furthermore, collaborative initiatives and the establishment of comprehensive, well-curated databases are vital for the effective sharing and consolidation of variant information. Such efforts are crucial for improving the collective understanding of variant impact and ultimately enhancing diagnostic yields and patient outcomes. The exponential increase in the volume of next-generation sequencing data has significantly magnified the challenges associated with variant interpretation. This data surge underscores the urgent need for clear guidelines and standardized methodologies to effectively prioritize and classify identified variants. Integrating diverse and complementary data sources is fundamental to resolving variants of uncertain significance. This holistic approach involves combining evidence from functional studies, population frequency data, and detailed clinical phenotypes to gain a more comprehensive understanding of a variant's potential clinical relevance. The development and maintenance of sophisticated bioinformatics tools and authoritative databases, such as ClinVar and gnomAD, play an indispensable role in facilitating accurate variant interpretation. These resources serve as critical benchmarks for assessing variant frequency, pathogenicity, and clinical significance. The interpretation of rare genetic variants is an intricate process that inherently requires a multidisciplinary approach. Close collaboration among clinical geneticists, bioinformaticians, and laboratory scientists is essential for pooling diverse expertise and ensuring a thorough and accurate evaluation of each variant. Advancements in functional genomics and the utilization of in silico prediction tools offer supplementary methods to gather crucial evidence regarding variant pathogenicity. These approaches can provide valuable insights into the functional impact of a variant, complementing traditional diagnostic methods. While established frameworks, such as the ACMG/AMP guidelines, provide a valuable structure for variant classification, their application to newly identified variants often demands significant expert judgment and iterative refinement. This highlights the dynamic nature of variant interpretation and the continuous need for adaptation and consensus-building.
Variant interpretation in clinical genomics is crucial for diagnosing genetic disorders and guiding treatment, but classifying variants of uncertain significance (VUS) remains a major challenge. Standardized workflows and the integration of machine learning and AI are emerging solutions to analyze vast datasets and identify complex patterns. However, ethical considerations, data privacy, and the transparency of AI models are paramount. Collaborative efforts and comprehensive databases are essential for sharing and curating variant information. The increasing volume of sequencing data necessitates clear guidelines and the integration of diverse data sources, including functional studies, population frequencies, and clinical phenotypes. Bioinformatics tools and databases like ClinVar and gnomAD play a vital role. A multidisciplinary approach involving geneticists, bioinformaticians, and scientists, along with functional genomics and in silico tools, aids in interpretation. The ACMG/AMP guidelines provide a framework, but expert judgment is often required for novel variants.
None
None
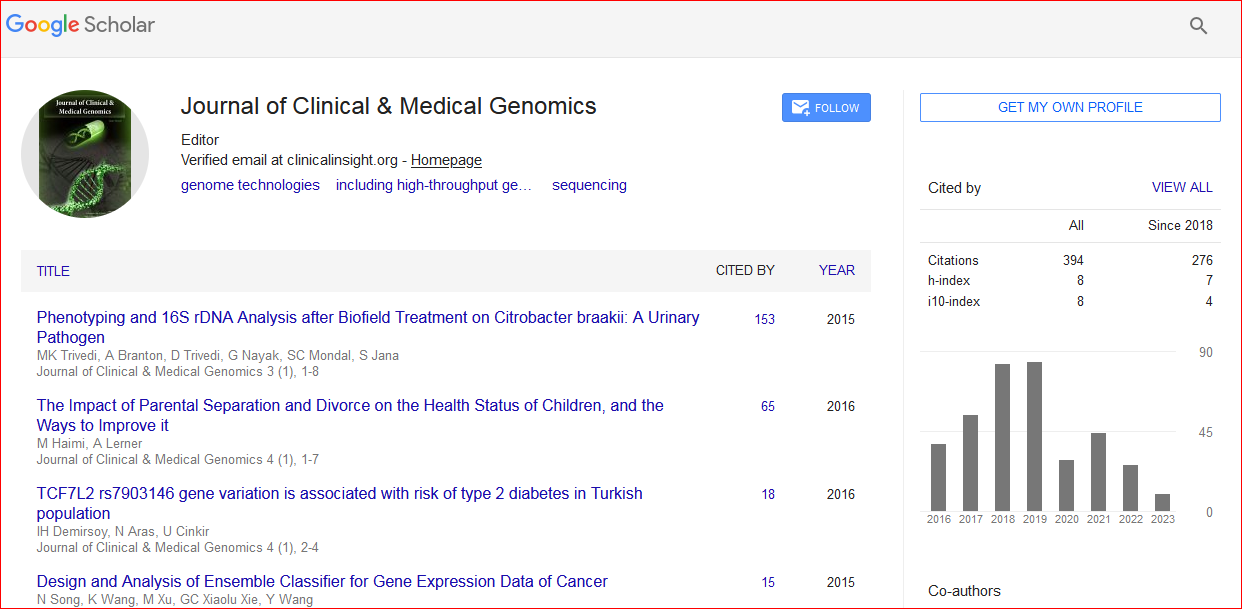
Journal of Clinical & Medical Genomics received 391 citations as per Google Scholar report