Editorial - (2022) Volume 11, Issue 3
Received: 07-Mar-2022, Manuscript No. sndc-22-65177;
Editor assigned: 09-Mar-2022, Pre QC No. P-65177;
Reviewed: 14-Mar-2022, QC No. Q-65177;
Revised: 19-Mar-2022, Manuscript No. R-65177;
Published:
24-Mar-2022
, DOI: 10.37421/2090-4886.2022.11.149
Citation: William, Oliver. “A Note on Cluster analysis of Data.” J Sens Netw Data Commun 11 (2022): 149.
Copyright: © 2022 William O. This is an open-access article distributed under the terms of the creative commons attribution license which permits unrestricted use, distribution and reproduction in any medium, provided the original author and source are credited.
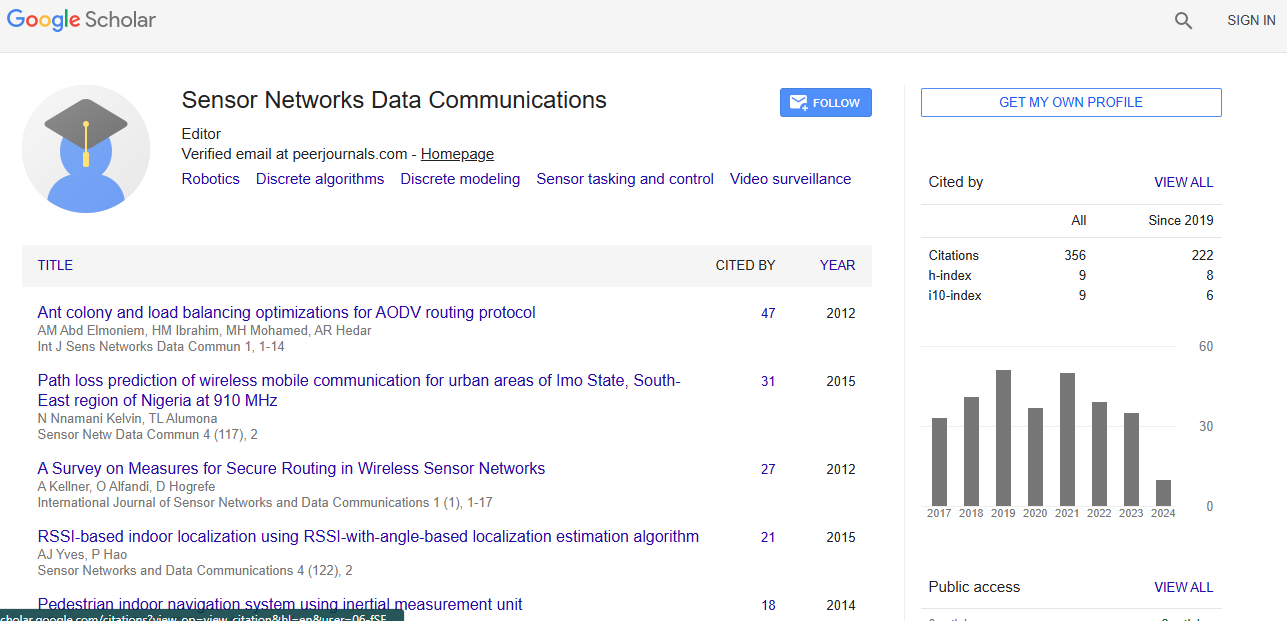
Cluster analysis, often known as clustering, is the problem of arranging a set of items so that objects in the same group (called a cluster) are more comparable (in some sense) to those in other groups (clusters). It is a typical approach for statistical data analysis used in many domains, including pattern recognition, image analysis, information retrieval, bioinformatics, data compression, computer graphics, and machine learning, and is a key goal of exploratory data analysis. Cluster analysis is the general problem to be solved, not a specific solution. It may be accomplished using a variety of methods, each of which has a different understanding of what defines a cluster and how to identify them effectively. Clusters are commonly thought of as groupings with tiny distances between members, dense portions of the data space, intervals, or statistical distributions. As a result, clustering may be thought of as a multiobjective optimization problem [1].
The best clustering technique and parameter settings (such as the distance function to employ, a density threshold, and the number of predicted clusters) are determined by the data set and the intended application of the findings. Cluster analysis is an iterative process of information discovery or interactive multi-objective optimization that includes trial and error, rather than an automatic activity. Changing data preparation and model parameters until the outcome has the desired attributes is common.
Clustering is a crucial data analysis tool. The number of clusters is a crucial consideration in clustering, and it may be computed either intentionally or automatically. Artificial approaches have several drawbacks. The automated approaches, whose key objective is to build an acceptable clusters number updating algorithm, offer significant benefits. Despite the fact that numerous studies have been conducted, the majority of them is ineffective or cannot guarantee unique clustering findings or a high clustering accuracy rate. The dissimilarities and densities of data items are used to develop an algorithm for selecting the first grouping centres. Then, using revised inter-cluster entropy for mixed data, a better clustering technique is created [2].
Load profile clustering is a typical analytical strategy for investigating consumption trends. Clustering load profiles is difficult despite the plethora of available algorithmic techniques because clustering methods do not always capture the temporal characteristics of energy usage and clusters are difficult to explain without additional descriptive home data. The use of cluster analysis to better understand behavioural and other determinants of power use trends is limited due to these issues.
Cluster analysis has evolved into a powerful tool for evaluating gene expression data and extracting biological information. Many specialists have mined gene expression data using both standard and innovative clustering techniques in recent years. The preparation of gene expression data is the first topic covered in this article. After that, a limited number of distinctive variables are retrieved as new indicators using principal component analysis (PCA) to analyse the gene data, and the indicators are assessed to satisfy the goal of dimensionality reduction. The winning neurons are chosen using the shortest Euclidean distance, and the dimension reduction index is applied to the dynamic self-organizing neural network (DSOM) neural network. With the increased availability of high-resolution data and analytical tools to define it, studying the dynamics of home power usage at finely-resolved timeframes is becoming increasingly viable. Load profile clustering is a typical analytical strategy for investigating consumption trends. Clustering load profiles is difficult despite the plethora of available algorithmic techniques because clustering methods do not always capture the temporal characteristics of energy usage and clusters are difficult to explain without additional descriptive home data [3].
The use of cluster analysis to better understand behavioural and other determinants of power use trends is limited due to these issues. These issues are addressed by using a novel clustering technique to analyse a unique data collection of high-resolution power and occupant time-use data from UK households. To capture their complete structure, we cluster cumulative rather than raw load profiles. Our clustering method finds two unique patterns of evening weekday power use (5-9 p.m.), which are essentially distinguished by the timing of their peak demand. Following that, we test the feasibility of leveraging time-use activity data to forecast membership in these various usage clusters using a variety of classification techniques. The methods we employ are well-suited to this predictive modelling setting, and they can identify critical activities that drive power demand trends. We highlight how such an approach might guide more focused residential peak demand reduction and response actions, as well as increase our knowledge of demand-side flexibility restrictions and possibilities in the residential sector [4,5].
None.
Google Scholar, Crossref, Indexed at
Google Scholar, Crossref, Indexed at
Google Scholar, Crossref, Indexed at