DOI: 10.4172/2329-9002.1000e105
DOI: 10.4172/2329-9002.1000112
KELL is a member of the M13 family of type II neutral endopeptidases, which functions as a blood group antigen in human and animal populations. KELL amino acid sequences and structures and KEL gene locations were examined using bioinformatic data from several mammalian genome projects. Mammalian KELL sequences shared 55-99% identity, as compared with 21-31% sequence identities with other M13-like family members. Four predicted N-glycosylation sites were conserved among the mammalian KELL proteins examined. Sequence alignments, key amino acid residues and conserved predicted secondary and tertiary structures were also studied, including active site residues, predicted disulfide forming Cys residues, cytoplasmic, transmembrane and extracellular sequences and KELL C-terminus amino acid sequences. Mammalian KEL genes usually contained 18 or 19 coding exons on the direct strand. abhi binding sites within the human KEL promoter may regulate transcription within erythroid cells. Phylogenetic analyses examined the relationships and potential evolutionary origins of the mammalian KEL gene with six other vertebrate neutral endopeptidase M13 family genes. These suggested that KEL originated in an ancestral marsupial genome from a gene duplication event of a neutral endopeptidase M13-like gene.
John W Pepper, Deborah E Shelton, Armin Rashidi and Pierre M Durand
DOI: 10.4172/2329-9002.1000113
Natural selection acts primarily on organisms, and the existence of evolved, active, internal mechanisms that cause organismal death would seem paradoxical. However, there is substantial evidence that internal death promoting mechanisms exist and are taxonomically widespread. Where these are argued to be ‘programmed organismal death’ (POD), they require evolutionary explanations. Any such explanation must draw on our understanding of fitness trade-offs and multiple levels of selection in evolution. This review includes two main categories of putative POD: senescence in multicellular-organisms, and programmed cell death in unicellular organisms. The evidence for POD as a genetically controlled phenotype is strong for semelparous and significant but more controversial for iteroparous plants and animals. In multicellular organisms the program frequently (although not always) appears to be the result of fitness trade-offs. Here the death phenotype itself is not adaptive but the fitness related program most likely is. However, in some cases of behavioral suicide, particularly in insects, there are distinct advantages to kin and group level benefits may play a role. In unicells, programmed death is ubiquitous and POD often provides benefits to others. While benefits do not equate with adaptations, they are consistent with it. Here, death may be adaptive at a level other than the individual cell. In other instances of POD in unicells the phenotype (eg autophagy) can be explained as pleiotropy. The overall picture of POD as a natural phenomenon is still emerging, and continued work on diverse lines of evidence is necessary to complete our evolutionary understanding of this apparent paradox. While some questions remain, we conclude that POD is most likely, in some circumstances at least, adaptive.
John David McVay and Bryan C. Carstens
DOI: 10.4172/2329-9002.1000114
There are two paradigms for the phylogenetic analysis of multi-locus sequence data: one which forces all genes to share the same underlying history, and another that allows genes to follow idiosyncratic patterns of descent from ancestral alleles. The first of these approaches (concatenation) is clearly a simplified model of the actual process of genome evolution while the second (species-tree methods) may be overly complex for histories characterized by long divergence times between cladogenesis. Rather than making an a priori determination concerning which of these phylogenetic models to apply to our data, we seek to provide a framework for choosing between concatenation and species-tree methods that treat genes as independently evolving lineages. We demonstrate that parametric bootstrapping can be used to assess the extent to which genealogical incongruence across loci can be attributed to phylogenetic estimation error, and demonstrate the application of our approach using an empirical dataset from 10 species of the Natricine snake sub-family. Since our data exhibit incongruence across loci that are clearly caused by a mixture of coalescent stochasticity and phyogenetic estimation error, we also develop an approach for choosing among species tree estimation methods that take gene trees as input and those that simultaneously estimate gene trees and species trees.
Felix Stehle, Franziska Götsch, Victor Wray, Jürgen Schmidt, Dieter Strack and Wolfgang Brandt
DOI: 10.4172/2329-9002.1000115
In this work, it is shown that the At2g23010 gene product encodes 1-O-sinapoyl-β-glucose:1-O-sinapoyl-β-glucose sinapoyltransferase (SST). In contrast to all other functional characterized acyltransferases, the SST protein is highly specific towards this reaction only, and the substrate specificity was correlated to one amino acid substitution. Detailed sequence analysis revealed the lack of the disulphide bond S1 (C78 and C323 in the SMT (sinapoylglucose:malate sinapoyltransferase), that is in SST C80 and D327). The reconstitution of this disulphide bond led to an enzyme accepting many different substrates including disaccharides. Interestingly, the overall changes within the model structures are not very dramatic, but nevertheless, the enzyme models provide some explanations for the broadened substrate specificity: the reconstitution of the disulphide bond provoked more space within the substrate binding pocket simultaneously avoiding electrostatic repulsion. As the SST sequence of A. lyrata also showed the same mutation, the loss of the disulphide bond should has arisen at least 10 mya ago. A Ka/Ks ratio ≤ 1 supports the hypothesis that the loss of this disulphide bond was rather a specification towards a certain reaction than the beginning of a gene death. At the same time, this is also associated with the fixation in the genome.
DOI: 10.4172/2329-9002.1000116
The use of genome-scale approach in phylogenetic analysis is imperative in order to resolve evolutionary relationships over large taxon sets and deep phylogenetic divergences. But yet it is not clear what are the strengths and weaknesses of the various phylogenetic methods or which one should be preferred under genome-scale approach. In this article, the performance of five major phylogenetic methods is evaluated under genome-scale approach using biologically realistic simulated data. The following phylogenetic methods are considered; Bayesian, maximum likelihood (ML), neighbor joining (NJ), NJ maximum composite likelihood (NJ-MCL), and maximum parsimony (MP). Simulation results show that probabilistic methods (i.e., Bayesian and ML methods) are much more accurate than the NJ-MCL, MP and NJ methods. Concerning the consistency of methods, ML is consistent than other methods. This analysis shows that the NJ-MCL, MP, and NJ methods are fast (i.e., computationally efficient), but their accuracy and consistency are very poor compared to Bayesian and ML methods. On the other hand, the Bayesian method is an accurate one, but less consistent than the ML method, and it takes much longer execution time. Therefore, based on the accuracy, consistency and computational efficiency the ML method is the preferred algorithm under genome-scale approach. In addition to the methods performance, this study has investigated several important aspects of genomescale phylogeny; such as how concatenations of longest and smallest genes make effect on the method’s performance, how much datasets are needed to recover the true tree (i.e. true evolutionary history of a group of species or genes), and whether more genes or more characters are important. These are explained in the result section.
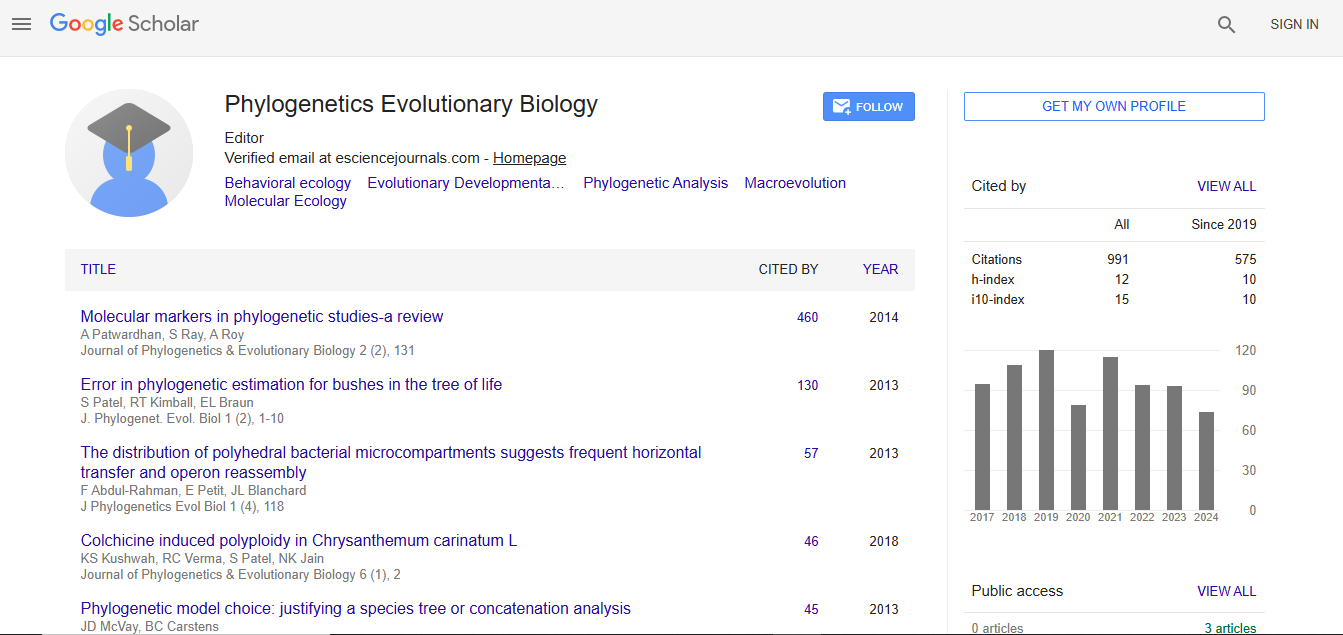
Journal of Phylogenetics & Evolutionary Biology received 911 citations as per Google Scholar report

 Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi 